
CHAPTER 2. CLIENT/SERVER OPERATION
1C:Enterprise supports operation with infobases in the client/server mode. In 1C:Enterprise case, the client/server mode is considered as an architecture with three software levels:
- One of the 1C:Enterprise client applications (ordinary (thick) client, thin client or web client);
- Web server (only for a web client or a thin client connected via a web server);
- 1C:Enterprise server cluster;
- Database server.
Fig. 1 demonstrates interaction between the above system components.
Client applications, thin clients, and web clients are the 1C:Enterprise itself (in various operation modes) that the end user actually works with. Nothing but a web browser is needed for web client operation.
1C:Enterprise server cluster is a logical concept representing a combination of working servers functioning on one or more computers and a list of infobases located in the cluster.
The 1C:Enterprise server cluster forms an intermediate software layer between the client application and the database server. The client applications have no direct access to the database server. To access an infobase, a client application interacts with the 1C:Enterprise server cluster.

Fig. 1. Chart of interaction between system components
This architecture of the system is focused on two aspects: as many features as possible should be processed by the server cluster while the client itself should be as "light" as possible. The server cluster ensures the entire operation of application objects, prepares the forms to be displayed (reads objects from an infobase and fills in the form data, arranges the elements, records the form data after editing), creates command interface and generates reports. The client only displays the information prepared in the server cluster, interacts with the user and sends requests to server methods for the required actions to be executed.
Besides, the servers that are part of the 1C:Enterprise server cluster, store the files with the event logs for the infobases registered on this 1C:Enterprise server and other service files. These data are not essential for operations on infobases and their loss would not render infobases inaccessible. Background jobs also run on the servers that are part of the cluster.
1C:Enterprise server cluster is installed by the 1C:Enterprise installer. Server cluster is configured using the server cluster administration utility that is included in the distribution kit.
The hardware dongle of the 1C:Enterprise server cluster is not network-enabled so it must be plugged into the USB ports of all the computers where cluster working processes run.
The web server is required for web client operation and for operation of one of the thin client versions. In fact, the web server itself interacts with the server cluster when operation is carried out via a web server. And then the web server interacts with the thin and the web clients.
NOTE
Unless otherwise stated, the term client application refers to the ordinary (thick) client, the thin client or the web server.
Database server. The essential data of the 1C:Enterprise infobases are stored on a database server in the client/server mode. Various database management systems can be used as 1C:Enterprise database server (see page 15). At that, every complete infobase is stored in a separate database of the DBMS used.
2.1. SERVER CLUSTER ARRANGEMENT
2.1.1. General
The basic unit of a server cluster is a working server. The working server is a computer where a server agent (ragent) is running. The server agent "represents" a working server in a server cluster. Generally, a computer hosts only one working server, but some scenarios (e.g. debugging) allow several working servers to operate on a single physical computer. Working servers running on the same computer must have different network port numbers for each working server and they must interact with different data directories of the cluster.
TIP
It is not recommended to run multiple working servers on a single physical computer in a productive system.
Each server cluster is comprised of one or more working servers. Please note that the number of working servers running on a single physical computer is not important for the cluster’s description or its operation. The cluster agent maintains a list of clusters to identify in which cluster a specific working server is functioning as the main server. The list of clusters is stored in 1cv8wsrv.lst file. This file contains information about the server clusters to which the given working server belongs as well as a list of administrators for the working server. The file is located in the cluster data directory (see page 56). In fact, the server agent is not a part of the working server, as it only ensures server operation (which includes representing the working server in the server cluster).
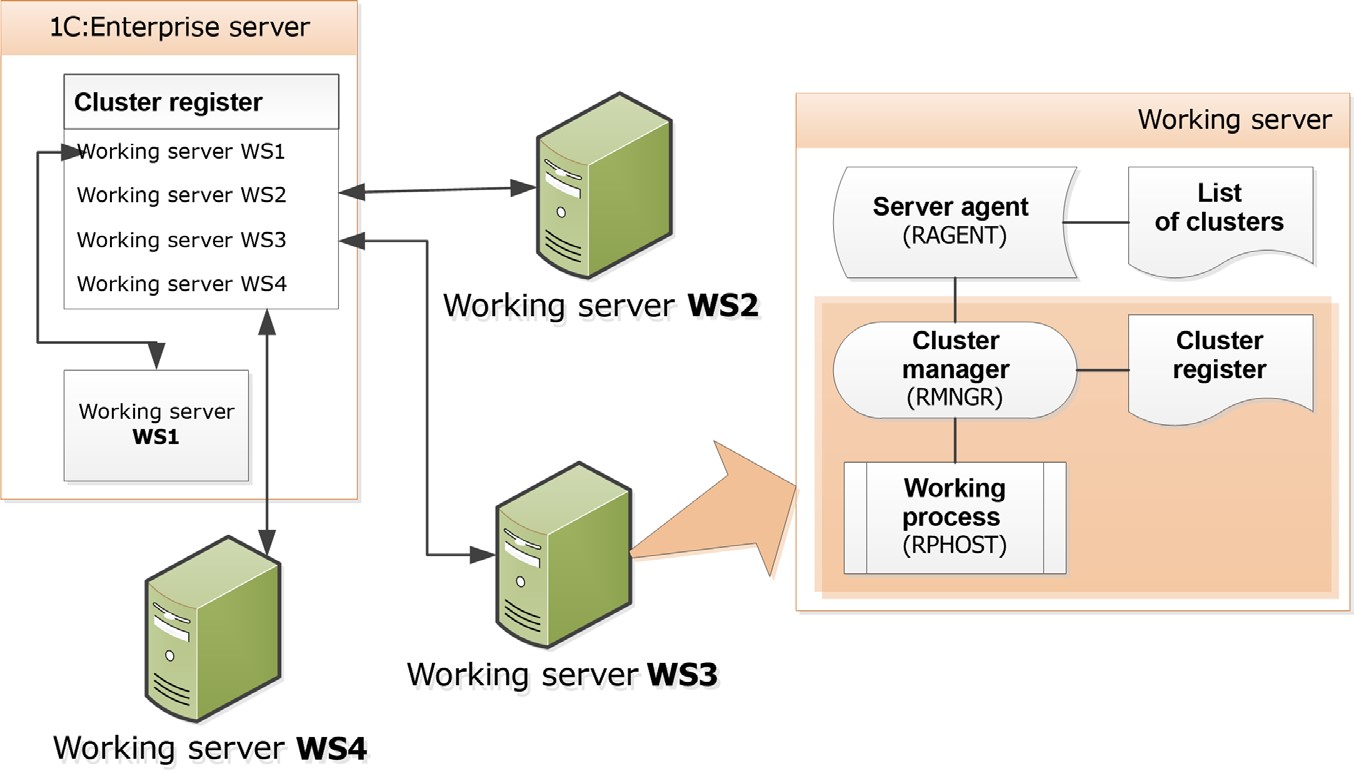
Fig. 2. General scheme of the 1C:Enterprise server
Any cluster should include at least one working server with the Central server property set. There is no maximum number of central servers. This means that you can select the Central server check box for everyworking server in the cluster. The working server can be a central server in one server cluster, and an ordinary (i.e., not central) one in another. In addition, a working server with the Central server check box selected can act as an end point for connections to the server cluster containing this working server.
The working part of the working server consists of a cluster manager (rmngr) and a working process (rphost). The cluster manager is responsible for proper working server operation and for interaction with other working servers of the cluster. The working process directly serves client applications, interacts with the database server, and executes the code marked as executable on the server in applied solution. The number of working processes is defined by the working server settings, the server cluster and the physical characteristics of the computer running the server.
A working server can have at least one cluster manager. The cluster manager working on the central server is called the main cluster manager. The maximum number of cluster managers is equal to the number of cluster services (see page 21). But if a single working server belongs to a number of clusters, then at least one cluster manager is created per cluster.
The main cluster manager maintains a cluster register. The cluster register is stored in 1CV8Clst.lst file and contains the following information:
- list of infobases registered in this cluster;
- list of working servers of the cluster;
- list of work processes of the cluster;
- list of cluster managers;
- list of cluster services;
- list of cluster administrators.
If a cluster contains multiple central servers, each main cluster manager maintains the cluster register on its own. The system is constantly synchronizing the copies of the cluster register maintained by the main cluster managers of central servers to ensure the relevance of data in each copy.
In the most primitive case, the working server and the server cluster are running on the same computer, as demonstrated in fig. 3.
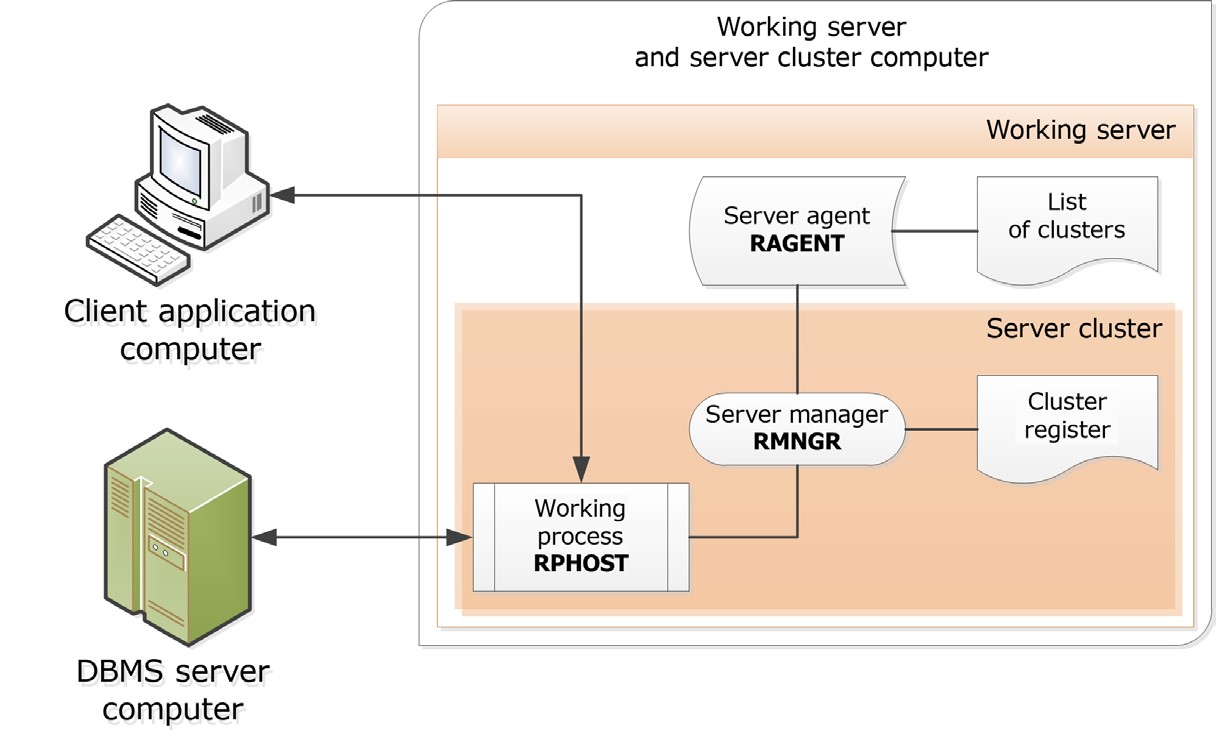
Fig. 3. Basic cluster
2.1.2. Interaction Between Client Application and Server Cluster
The cluster manager selects a working process for serving the client application, and reports its address to the client application.
When server cluster is installed, the following network port numbers are used by default:
server agent – port 1540;
cluster manager – port 1541.
For a working process a port number is selected dynamically from the specified range. The default network ports range is 1560:1591.
When required, you can change the numbers and the range of the ports used.

Fig. 4. Basic cluster
In the figure above the central cluster is named 1C_Serv. So the central server itself has the address 1C_Serv:1540. The cluster located on this server has the address 1C_Serv:1541 while the address of the working process is 1C_Serv:1561.
When a client application attempts to connect to a client/server infobase, it sends a request to a particular server cluster: 1C_Serv:1541.
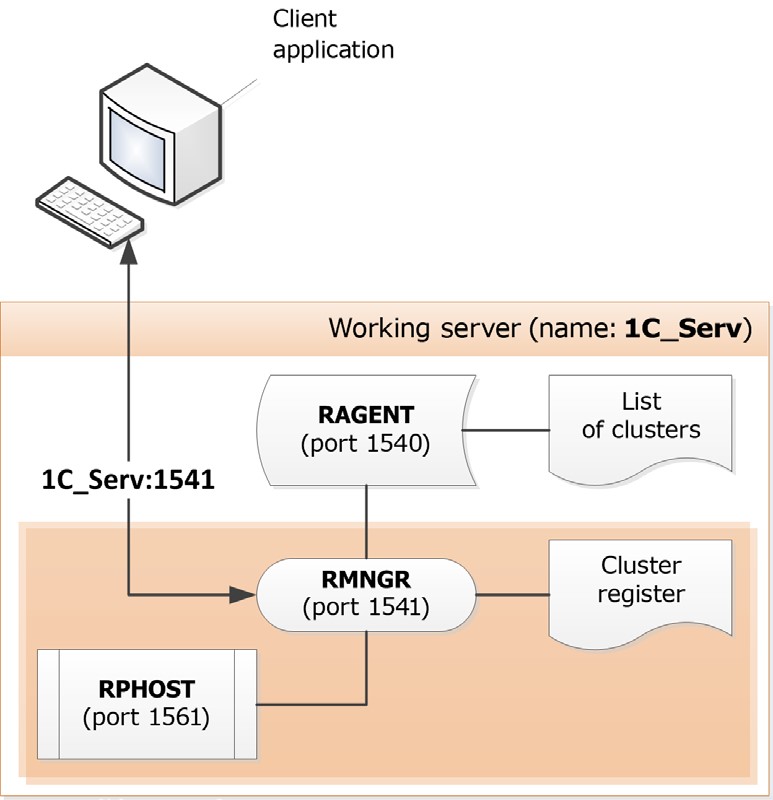
Fig. 5. Request to a basic cluster
Based on an analysis of the working processes load statistics, the cluster manager provides the client application with the address of the working process it will work with. In this case, since there is a single working process only, it will be 1C_Serv:1561.

Fig. 6. Established connection
The client application connects to the allocated working process that performs infobase user authentication and carries out all further interactions of the client application with the infobase.
IMPORTANT!
For successful operation, the client application and server versions should fully match. The system will not operate if, for example, the server version is 8.3.1.195 while the one of the client application is 8.3.1.100.
2.1.3. Cluster Services
Functions of a cluster manager are executed by a number of independent services. Each service has its particular characteristics. Below is a list of services, including a short description of each and its characteristics.
|
Service |
Explanation |
Characteristic |
|
Object lock |
Stores pessimistic (non-transactional) object locks. |
Memory Replication Migration + Allocation among infobases |
|
Cluster locks |
Stores infobases locks, information on active processes, and other dynamically updated information on cluster operation. |
Replication No migration |
|
Time |
Supports getting realtime timestamp and some auxiliary functions. |
Replication Migration + Allocation among infobases |
|
Event logs |
Provides access to event logs. |
Disc Migration - Allocation among infobases |
|
Jobs |
Manages launch and lifetime tracking for background and scheduled jobs. |
Transfer+ |
|
Configurations |
Stores all the cluster settings. |
No migration Replication |
|
Numbering |
Ensures generation of unique numbers and codes for the objects. |
Replication Migration + Allocation among infobases |
|
Full text search |
Carries out full text search and indexing. |
Disc Migration - Allocation among infobases |
|
Custom settings |
Provides access to the files storing some custom settings. |
Migration - Allocation among infobases |
|
Session data |
Ensures storage and caching of session information, e.g. the information from managed application forms. Provides obtaining of client licenses. |
Disc Replication Transfer+ Allocation among infobases |
|
Transactional locks |
Contains transactional locks of managed mode. |
Memory Migration + Allocation among infobases |
|
Debug items management |
Manages debugger attachments to server debug items. |
No migration |
|
External data sources access via ODBC |
This service ensures interaction with external databases via ODBC interface. |
Memory Migration+ Allocation among infobases |
|
Licensing service |
Ensures issuing of client licenses. If the licensing service of the cluster is temporarily unavailable and some licenses have been already obtained through this service, then temporarily you can only obtain licenses issued via the service within 20 seconds. |
Migration+ |
|
Background database configuration update service |
This service is for background database restructuring. Migration of this service to another cluster manager is possible only if all working processes are stopped. The system background job will also be stopped. The background update process itself is therefore also suspended after migration. |
Migration+ Allocation among infobases |
|
External session management service |
This service manages the feature of creating the sessions requiring client licenses for their operation. |
Migration+ Allocation among infobases |
|
Service for using external data sources via XMLA |
Ensures interaction with OLAP sources using the XMLA interface. |
Migration - Allocation among infobases |
|
Testing service |
Imitates the user’s operation with the 1C:Enterprise cluster. |
Migration - |
The table includes the following terms:
Disk is a resource intensive service that causes heavy load on the disk subsystem.
Memory is a resource intensive service that causes heavy load on the processor and RAM.
Replication – replication between the main and the backup instances of the service is supported. Replication occures if the cluster resilience level is different from 0 (see page 33). If the cluster configuration service and the cluster lock service are involved, replication is performed when there are multiple working servers with the Central server flag checked.
Allocation among infobases – there is a separate instance of service for each infobase.
Migration among working servers:
○ Migration+ – the service can migrate from one working server to another without any loss of data.
○ Migration- – the service can migrate from one working server to another with losing some data.
○ No migration – the service cannot migrate from one working server to another and is located on the computer of the cluster’s central server. No requirements for assigning functionality can be created for such services (see page 38).
Cluster services are proportionally allocated among cluster servers based on service types, infobases and sessions.
2.1.4. Sessions and Connections
A session describes an active infobase user and the thread of this user. An active user can be:
An instance of the 1C:Enterprise client application;
An instance of a web application the web client runs in;
External connection instance (received from the V83.COMConnector object);
One instance of a background job; One request to a web service.
All the data stored in a cluster and related to one active user and relevant only for the time this user operates the software, are referred to as the session data. The session data include:
Infobase
Session number
Authenticated infobase user
Interface language
Values of session parameters
Temporary storages
Session operation statistics
Managed application forms data
Some internal platform data
Session data are stored by a cluster manager. This is the purpose of the session data service (see page 21). When server cluster is restarted, session data are stored. If the currently active user does not send any requests to the cluster for 20 minutes and the session is not attached to a connection, this session and the session data are removed. To maintain a session, the thin and the web clients provide for requests sent to the cluster at least once every 10 minutes. To improve access time, session data are cached in the working processes and in the thick clients. A list of sessions is included in the active users list.
Changes in session data implemented during one server call are stored in a working process and are sent to the cluster manager only when control is returned to the client (both normally and as a result of a software exception).
Changes in session data are not stored in the cluster manager if:
A working process fails during a server call;
A data transfer error occurs when control is being returned to the client.
A connection is a mean for sessions to access 1C:Enterprise server cluster. A connection contains a limited set of connection data and is not identified with an active user. Connections are also used for cluster processes interaction.
A session is assigned to a connection for a client to send a request to the cluster. A session cannot be assigned to any connection throughout the entire time when the client does not send any requests to the cluster.
Various 1C:Enterprise modes handle sessions and connections in different manners.
Designer and thick client:
○ Upon startup: establishes a connection, initiates a session and attaches it to the connection;
○ Upon shutdown: detaches the session from the connection, shuts the session down and disconnects.
One call to a web service and execution of one background or scheduled job:
○ In the beginning of a call: selects a connection from a pool, creates a session and attaches the session to the connection;
○ In the end of a call: detaches the session from the connection, shuts the session down and returns the connection to the pool.
A thin or a web client initiates a session at startup and finishes it in the end:
○ In the beginning of a cluster call, a connection is selected from the pool and the session of this client is attached to this connection.
○ In the end of the cluster call, a session is detached from the connection and the connection is returned to the pool.
Information on sessions is available in:
event log
cluster console
software administration tools
technological log
global context
A cluster administrator may obtain the list of existing sessions both for the entire cluster and filtered by infobases. This is provided for by the cluster administration utility and the software administration tools.
A cluster administrator may force a session to end using cluster administration utility and software administration tools. At that, current user operation will end abnormally. If a removed session is assigned to a connection, disconnection will be executed for this connection.
Using administration utility and the software administration tools, the administrator can lock sessions. With sessions locked, no new sessions will be initiated, but the current sessions will not be affected.
2.1.4.1. Connection Types
There are two types of connections:
Infobase connections,
Service connections with cluster working processes. Infobase Connections
The specific features of infobase connections are as follows:
A connection is established with a specific infobase of a cluster;
1C:Enterprise script can run within such a connection;
A connection can be restarted with time;
Disconnection can be forced using cluster console command or 1C:Enterprise script language tools;
If a working process is connected to an infobase, this working process cannot be ended or started.
The following types of infobase connections are available:
Thick client
Thin client
Designer
Web server extension module
COM connection
Background job
Thick Client
This is a thick client connection to an infobase. This connection is intended to modify infobase data and carry out various other functions supported by the infobase configuration.
The Thick client connection is created when thick client is launched interactively in the 1C:Enterprise mode or when an infobase is connected to using Automation client/server technology, e.g.:
// Create 1C:Enterprise Automation server
AutomationServer = New COMObject("V83.Application");
// Connect to an infobase
// TestBase in cluster 1541 of the TestSrv central server
AutomationServer.Connect("Srvr="TestSrv";Ref="TestBase");Thin Client
This is a thin client connection to an infobase. This connection is intended to modify infobase data and carry out various other functions supported by the infobase configuration.
The Thin client connection is created when thin client is launched interactively or when an infobase is connected to, using Automation client/server technology, e.g.:
// Create 1C:Enterprise Automation server
AutomationServer = New COMObject("V83C.Application");
// Connect to an infobase
// TestBase in cluster 1541 of the TestSrv central server
AutomationServer.Connect("Srvr="TestSrv";Ref="TestBase");Designer
This is a Designer connection to an infobase. This connection is intended to create and modify infobase configuration and to carry out administrative and scheduled jobs.
Web Server Extension Module
This is a web server connection to a server working process. This connection supports operation of the web client, web services, and the thin client (via HTTP).
This connection is created when a request is sent to a web service or when a web client or a thin client sends a request to the 1C:Enterprise server (via HTTP). The connection exists until the web server is restarted or while the connection is in the connections pool of web server extension modules (throughout the connection lifetime in the pool or until this connection is pushed from the pool by other connections).
For details regarding web services, see "1C:Enterprise 8.3. Developer Guide".
COM Connection
This is a connection of a process relying on 1C:Enterprise external connection functionality with an infobase. This connection is intended to modify infobase data and carry out various other functions supported by the infobase configuration.
A COM connection is created when COM technology is used to connect to an infobase, e.g.:
// Create 1C:Enterprise Automation server
COMConnector = New COMObject ("V83.COMConnector");
// Connect to an infobase
// TestBase in cluster 1541 of the TestSrv central server
InfobaseConnection = COMConnector.Connect("Srvr="TestSrv";Ref="TestBase");Background Job
This is a cluster working process connection to an infobase. This connection is intended to execute the code of a background job procedure.
A background job connection is created when a background job is launched for execution. It can be launched either by 1C:Enterprise as a result of a scheduled job launched automatically (a scheduled job creates a respective background job) or by the developer using 1C:Enterprise script tools, e.g.:
// Execute a background job described in the procedure
// UpdateFullTextSearchIndex
// of the ScheduledProcedures shared module
BackgroundJob = BackgroundJobs.Execute("ScheduledProcedures.UpdateFullTextSearchIndex");A background job connection exists while the context of the executed background job procedure exists. When a procedure is completed, the background job connection is closed.
For details on background jobs, see "1C:Enterprise 8.3. Developer Guide".
Service Connections
The service connections have the following specific features:
A connection is established with a working process and is not associated with any specific infobase;
1C:Enterprise script is not executed within service connections;
Forced disconnection is impossible because a connection is created and ended by the system;
Service connections do not prevent server cluster working processes from ending and launching.
The following types of service connections are available:
Job Scheduler
Debugger
Cluster console
Administration Server
COM-administrator
System background job
Job Scheduler
This is a connection of a job scheduler with a working process. The connection is intended to manage operation of background jobs, including launching scheduled jobs in compliance with a schedule. This connection is also used for other cluster manager (rmngr) calls to the working process (rphost), e.g. while obtaining a list of sessions.
A job scheduler connection is created when a background job is first launched. It can create background job connection to an infobase in the same server cluster working process. When a background job connection is ended, the job scheduler connection will keep existing until the cluster working process is disabled or removed.
For details on background jobs, see "1C:Enterprise 8.3. Developer Guide".
Debugger
This is a debugger connection to a working process of a cluster in the debug mode. This connection is intended to manage the process of debugging and searching for debug items currently available.
The debugger connection is created when a debug item is attached or when debug items are searched for. The connection exists until a debug item is detached or shuts down.
For details on the debugger, see "1C:Enterprise 8.3. Developer Guide".
Cluster Console
This is a connection of a server cluster console (mmc, see page 112) with a working process. The connection is intended to administer server cluster infobases.
A cluster console connection is created when a request is sent to the working process data (for example, when receiving infobase parameters, detailed list of infobase connections, etc.).
Administration server
This is a connection of the remote cluster administration server to a working process. The connection is used for administration of server cluster infobases.
A remote administration connection is created at the moment working process data is being called (e.g., to get infobase parameters, a detailed list of infobase connections, etc.).
COM Administrator
This is a connection with a server working process using COM technology. The connection is intended to administer server cluster infobases.
A COM administrator connection is created when COM technology is used to connect to a selected working process, e.g.:
// Create 1C:Enterprise COMConnector
COMConnector = New COMObject ("V83.COMConnector");
// Connect to working process 1562
// in cluster 1541 of the TestSrv central server
WorkingProcessConnection = COMConnector.ConnectWorkingProcess("tcp://TestSrv:1562");System background job
This is a cluster working process connection to an infobase. This connection is used for background database configuration upgrades.
A background job connection exists as long as background restructuring is being performed.
For details regarding the background database configuration upgrade, see "1C:Enterprise 8.3. Developer Guide".
2.1.4.2. Session Types
The following session types are possible:
Thick client
Thin client
Web client
Designer
COM connection
WS connection
Background job
Cluster console
Administration Server
COM-administrator
The descriptions of sessions are mostly similar to descriptions of their respective connections. The only difference is a web client session.
Web Client
It is a representation of a web client instance in a server cluster. This session is intended to modify infobase data and carry out various other functions supported by the infobase configuration. The web client sends requests to the server using Web server extension module connection.
The Web client session is created when web client is launched interactively and exists until infobase interactive session is ended (the last web browser window is closed).
2.1.4.3. External session management
When operating client/server systems, you have to manage the creation of sessions with infobases, which implies the ability to:
Limit the number of users working simultaneously with the same infobase.
Ensure a guaranteed reserve of licenses when working with an infobase (e.g., with 100 licenses available, to provide guaranteed access to the infobase for two users with particular names).
Address other problems of this kind.
The external session management feature is designed specifically for these problems. The feature requires a dedicated web service that decides whether to allow session creation or not.
The feature functions as follows:
When the system attempts to start a session, the server cluster informs the web service that a session needs to be created and provides the web service with a set of parameters that allow you to define all the characteristics of the session to be created (the infobase name, user name, server cluster, etc.).
The web service decides whether to allow the session creation or not and returns control to the server cluster. If required, the web service should keep any necessary records for the sessions created.
At the end of the session, the server cluster also informs the web service of this.
The system for external session management therefore knows the exact number of sessions currently being created in infobases under its control, and it is able to make appropriate decisions.
For a description of the web service used for external session management and an example of how it is implemented, see page 163.
2.1.5. Failover Cluster
A failover cluster ensures uninterrupted operation of users in the following situations:
Restart of working processes and cluster managers (both scheduled and emergency restart);
Outage of a server that is part of the cluster.
This section covers the tools intended to ensure undisturbed operation.
2.1.5.1. Transactional Nature of Session Data
During operation, a session is saved upon various failures so work can be restored after reconnection. But there are situations when the system ends a session and prompts for restart of a client application:
During a server call a working process fails after the first transaction of this call has been committed;
A data transfer error occurs when control is being returned to the client.
2.1.5.2. Last Call Retry
If a data transfer error occurs in the process of server call, it may mean that:
Communication channel is broken, A server working process fails.
If a client application sends a call to a server outside of a transaction and the client receives the data transfer error prior to commitment of the first transaction within the server call, the client automatically connects to the server and retries the same call. The client proceeds its operation.
If the client receives the data transfer error after commitment of the first transaction within the server call, the session of this client shuts down and restart of the client application is needed to proceed.
2.1.5.3. Interactive Action Retry
If a client application calls the server within a transaction (in ordinary operation mode instead of the managed application mode), the data transfer error is considered to be a recoverable error. This error results in failure of the interactive action but does not result in failure of the client application itself.
It is important that application data consistency in this situation is not ensured by the platform if the interactive action includes more than one transaction and modifies application data status (except for the data with caching logic supported).
2.1.5.4. Resilience Level
The level of resilience defines the maximum number of working servers of the cluster, whose concurrent failure would not result in an abnormal termination of sessions of any users connected. It should be noted that the failure includes, but is not limited to, the computer’s power-off, network cable break, operating system problems preventing one from starting the process, etc.
Therefore, if the server cluster has only one working server, the maximum level of resilience will be 0, as the failure of the only server will result in abnormal termination of all sessions created by the users connected. If there are 4 working servers in the cluster, the resilience level can vary from 0 to 3, where 0 means that failure of any working server is fatal, and 3 means that the cluster will remain operable even when 3 out of 4 working servers fail.
Please note that any increase in resilience level is reached at the expense of a certain decline in cluster performance, as some cluster resources will be used to synchronize the data of working servers.
The resilience level is based on the number of central servers in the cluster. The number of central servers dictates whether the creation of new connections is possible. For instance, if 2 out of 3 working servers in the cluster are central, then users can still connect to infobases if just one central server fails. In this case two servers (a central server and a working server) are still operable. But if such a cluster had only one central server, then in the event of its abnormal termination, the cluster would be unavailable for users even though two working servers were operable.
Where the cluster includes 3 working servers (one of which is central) and the resilience level is set to 1, different scenarios can occur. Let’s have a closer look at these now.
Failure of one working server
The operation of an ordinary working server terminates abnormally. This corresponds to the resilience level and the cluster keeps on serving users. Connection of new users is also possible as the central server is functioning properly.
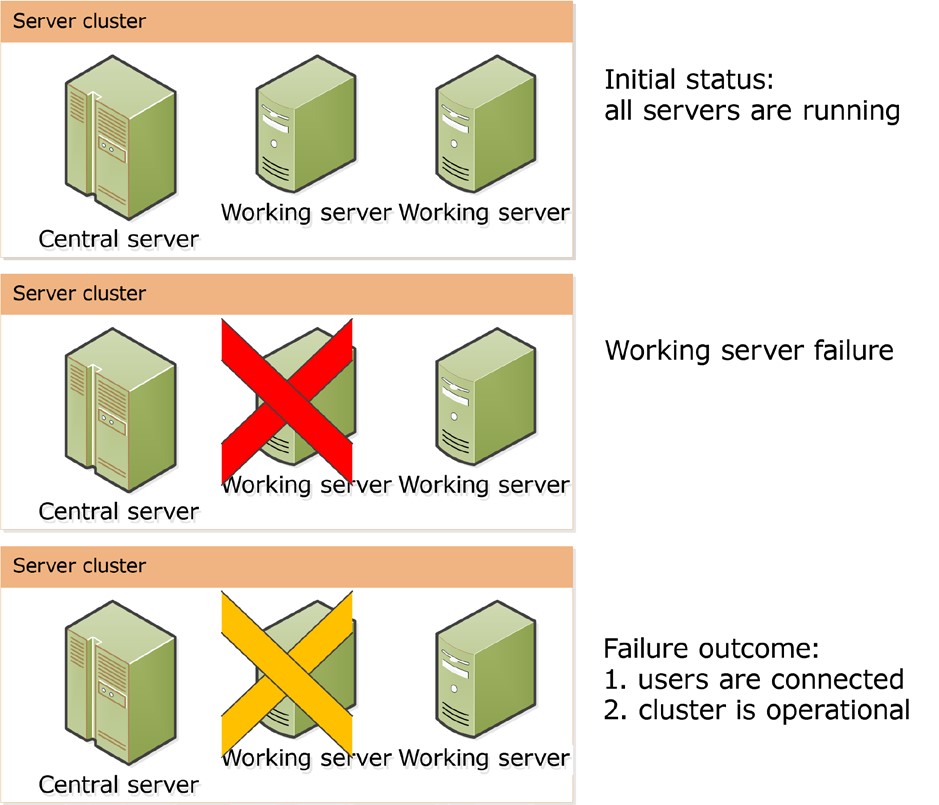
Fig. 7. Abnormal termination of one working server
Failure of the central server
The operation of the central server terminates abnormally. This corresponds to the resilience level, but the cluster stops its operation as the central server does not work.

Fig. 8. Abnormal termination of the central server
Failure of two working servers
The operation of an ordinary working server terminates abnormally, but the central server functions properly. The resilience level is exceeded, which terminates any sessions served by the working servers that failed. Users being served by the central server are not affected. Connection of new users is also possible (see fig. 9).
Thus, the formula demonstrating the interrelation between the number of central servers in the cluster and the resilience level looks as follows: Number of central servers = Resilience level + 1. However, remember that following this formula mechanically can result in slowing down of cluster performance because some system resources will be used to synchronize the data of working servers. When deciding on the number of central servers and the resilience level, you should strike a balance between the resilience and the acceptable level of cluster performance, taking into consideration the specifications of the cluster hardware.
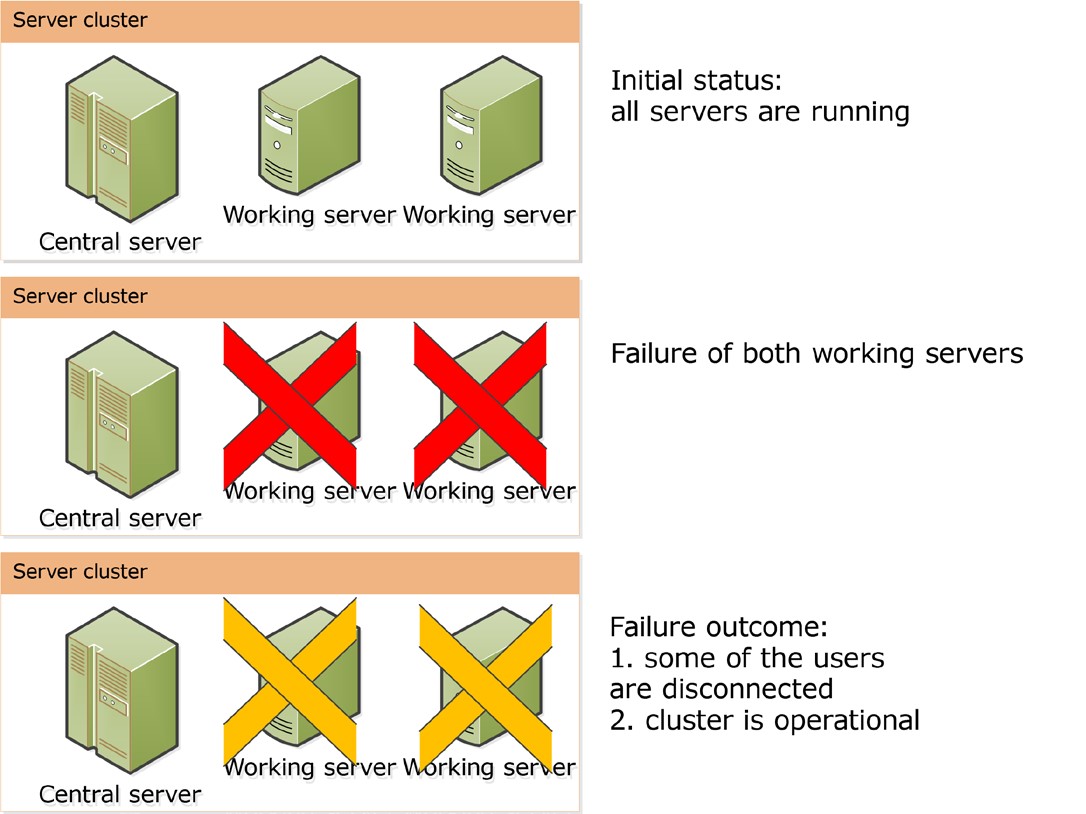
Fig. 9. Abnormal termination of two working servers
2.1.6. Server Cluster Scalability
There are several methods to ensure cluster server scalability:
To increase the computing capacity of the computer where a single working server is deployed.
To provide the possibility of adding one or more new working servers to the server cluster.
The server cluster automatically executes all actions required to ensure its own scalability. The cluster administrator can influence the server cluster actions by changing the working server properties.
New servers can be added to the list of working servers and the properties of existing servers can be changed (see page 123). Changing the property values will be effective only for new sessions and connections. A special method should be applied to remove the working server so as to prevent abnormal disconnection of users served by the server to be removed. For more information on how to remove a working server, see page 127. You cannot remove the last working server with the Central server flag checked. When a cluster is created by default, the working server of the computer where the server cluster is being created is automatically included in the list of working servers and the Central server check box for this working server is selected.
When in operation, the server cluster automatically allocates the workload in a way that keeps the time required to serve client applications at a minimum. Cluster services (see page 21) are proportionally allocated among cluster servers based on the type of service, the infobases and the sessions.
When an infobase connection is being established, the server cluster selects working servers with maximum capacity available at the moment. Existing connections can be moved to another working server. See page 37 for a detailed description of how this works.
For a description of other properties of a working server, see page 124.
2.1.7. Cluster load balancing
2.1.7.1. Available performance of the working process
Each working process has the Available performance property. This property shows how fast the given working process is able to process a reference server call as compared with other working processes.
Calling a reference comprises the following operations:
Memory operations: array selection, array populating, and array release.
File operations: creation, writing, and deletion.
Assessment of the processor load for the computer on which the working process is run, and the number of flows to be run. This value enables upward adjustment of the time of reference call execution. If the user in whose account the server is run does not belong to the Performance Log Users group, then the processor load assessment is not performed.
The value of the Available performance property is calculated by dividing 10,000 by the average time (within 5 minutes) required to process a reference call for the current working process. The reference call is executed every 2 seconds if there are several working servers in the cluster. All working processes are considered to be equal when the cluster consists of a single working server.
Clients are distributed among the working processes so as to ensure a roughly equivalent available performance for all of them. The 25% difference in available performance is considered to be substantial.
When relation between available performance of working processes changes, the clients are dynamically redistributed among working processes within 10 minutes at the most.
When a working process is disabled, its clients are dynamically redistributed among the working processes that are still enabled.
2.1.7.2. Establishing a New Connection
Direct Server Connection
When establishing a new connection with the 1C:Enterprise server, you can specify whether the working process (the Load balancing mode server cluster property) will be selected subject to:
Performance-based priority
Available memory-based priority
Performance-based priority selection mode
To establish a new connection with the 1C:Enterprise server, a working server with the highest performance level is selected. Where there are several servers of the same performance level, the working server will be selected among them arbitrarily. Then a working process to serve a maximum number of connections with the required infobase will be selected on the working server. If there are multiple working processes, the working process that serves the maximum number of connections with any infobases will be selected. Where such working processes are multiple, the working process will be selected among them arbitrarily.An existing 1C:Enterprise server connection may be switched to another working process in one of the following situations:
The current working process expires.
A working process exists with available performance exceeding the performance of the current working process by 25% or more.
Reconnection is possible if all the conditions below are met:
A client thread is not executed on the server.
No open transactions exist.
No temporary tables are created.
Memory-based priority selection mode
When a new connection with the 1C:Enterprise server is created, the system selects a process that has already been servicing the connection with an infobase required. Where such a working process is not identified, the system selects a working process launched on the server with the greatest free RAM available.
If there are multiple working servers that serve the connection with the required infobase, then a server with the highest performance level available will be selected. If the working server has multiple working processes serving the connection with the required infobase, a working process with the largest number of connections with such an infobase will be selected.
The existing 1C:Enterprise server connection can be reestablished to involve another working process in one of the following scenarios:
The current working process is disabled.
There is a working process whose available performance is 25% lower than the performance of the current working process, and it serves the same infobase as the current working process does.
The connection can be reestablished if all the prerequisites listed below are met:
The client flow is not executed on the server.
There is no open transaction.
A temporary table has not been created. Connection via a Web Server Extension
When calling the server on behalf of a new session, the system:
selects any connection among the connection pool available in the web server extension.
When there are no connections available, a new connection is created based on the Load balancing mode cluster parameter.
When the call is performed on behalf of the existing session, the system:
searches for a connection (within the connection pool) with the same working process via which the interaction was performed during the previous call. If the search is successful, the connection which has been identified will be used.
The system attempts to select a working process based on the Load balancing mode cluster parameter, placing a priority on the working process that was last used to call the server. A new working server will be selected if it is significantly better (in terms of performance or available memory) than the "old" working process. If there are free connections to the specific work process, the system will use one of these connections.
Otherwise, a new connection is created based on the Load balancing mode cluster parameter.
2.1.7.3. Requirements for Assigning Functionality
General information
The server cluster provides a set of features called requirement objects, and you can manage their allocation among working servers within the cluster. For example, you can specify that all background jobs in the cluster will be executed by the working server which you select.
To put a connection or cluster service on a working server, you should create a requirement for assigning functionality for the working server selected.
This requirement defines whether a particular server is capable of executing a particular job or not. Let us examine the requirement for assigning functionality in detail.
The requirement for assigning functionality defines the following:
Object for which the requirement is created. Some cluster services (see page 21), or client connections (see page 27) or an arbitrary requirement object can act as a requirement object. Cluster services that can act as requirement objects are as follows:
○ Object lock service
○ Time service
○ Event log service
○ Job service
○ Numbering service
○ Full-text search service
○ Custom setting service
○ Session data service
○ Transactional lock service
○ Service for external data sources access via ODBC
○ Service for using external data sources via XMLA
○ Licensing service
○ Background database configuration update service
○ Testing service
○ External session management service
Requirement type. The requirement type defines the way in which the working cluster will be used.
○ Do not assign means that the working server for which the requirement is created will not be assigned to process the requirement object satisfying conditions specified in the requirement.
○ Assign means that the working server for which the requirement is created will be one of the potential candidates (in the case of multiple working servers) to process that requirement object.
○ Auto means that the working server can be used to process the requirement object in case there is no working server explicitly assigned for this purpose.
TIP
It is a good idea to use the Auto requirement type when the list of working server requirements includes a requirement with a wider set of conditions and you need a requirement for a smaller set of conditions. For example, a server that cannot process client application connections for all infobases except for the one infobase for which this is allowed.
Additional parameters needed for the server cluster to make decisions in some situations are as follows:
○ Infobase name. This is used to adjust the requirement for generating requirements for client connections and all cluster services that can act as requirement objects except for the licensing service.
○ Additional parameters. These are used to adjust the requirement when client connections or the session data service are distributed. The system verifies whether the additional parameter matches the beginning of the relevant parameter of the requirement object. The additional parameter value can be as follows:
□ To specify a particular background job: BackgroundJob.CommonMo- dule.<Module Name>.<Method Name>.
□ To specify all background jobs: BackgroundJob.CommonModule.
□ To specify a particular report: BackgroundJob.Report.<Report Name>.
□ To specify all reports: BackgroundJob.Report.
□ To specify background restructuring: SystemBackgroundJob.
□ For a client application:
• 1CV8 – a thick client.
• 1CV8CDirect – a thin client in case of direct connection to 1C:Enterprise server.
• Designer – Designer.
• COMConnection – COM connection.
• WebServerExtension – connection to an infobase via a web server: web client, thin client in case of connection via a web server, web service.
Let us study the way the server cluster processes requirements.
If a requirement object should be allocated, the following actions are performed by the cluster.
All cluster servers process requirements for assigning functionality specified for these servers. Servers operate and requirements are processed in the sequence specified for these objects in the cluster console.
In every requirements list, the system selects the first requirement that satisfies the object to be assigned: based on the object itself, the infobase and the additional parameter.
Then the working server list is sorted based on the requirement type so that working servers explicitly allowed to be used are placed at the top of the list. Working servers of which usage is explicitly banned by the relevant requirement type are excluded from the list of available working servers. Servers are assigned in the following way:
○ There are working servers that are explicitly allowed to be used: the requirement object will be processed by one of these servers.
○ There are no working servers explicitly allowed to be used: the system attempts to employ working servers for which the requirement type is Auto or use working servers for which requirements are not specified.
For a detailed description of the rules for selecting working servers, see page 42.
When a client connection is being placed, the server including a working process with the highest available performance will be selected from the list of available servers (see page 37). For a detailed description of the rules for selecting working processes, see page 43.
The client application that initialized the requirement object distribution will be abnormally terminated if one of the following is the case:
The list of working servers is empty for the requirement object, i.e. there are no working servers that can process the object. In this case the requirement object will not be assigned and an exception will be called.
Assigning to the working server selected is impossible, e.g. the server selected fails and there are no alternative servers.
Assigning requirement objects
Let us have a closer look at the algorithm used to assign a working server for a cluster service.
Cluster services (see page 23) can have the following requirement objects:
Service of one type, if the service is not divided based on infobases.
Service of one type for one infobase, if the service is divided based on infobases.
Session Data Service.
Licensing Service.
Services are allocated among the relevant working servers as follows:
The system selects services that are currently operable from the list of working servers selected for the assignment. Among the others, servers with a maximum Priority property value are selected.
Services are distributed evenly among the selected working servers.
Services supporting replication can be assigned to several working servers. The maximum number of working servers being used is equal to the cluster resilience level plus 1 (see page 33). In this case, one service will be active, and its data will be replicated for other (backup) services. Replication will be performed asynchronously. Data is synchronized every second.
Services that do not support data migration are assigned to all working servers with the Central server check box selected (see page 19).
An individual instance of the session data service is created for each session processed by the server cluster. When selecting working servers that can process a service instance, additional parameters of the requirement should be considered. Servers processing minimum number of cluster services are selected from the list of available servers. The maximum number of working servers used is equal to the cluster resilience level plus 1 (see page 33).
If you need to use licensing service, select a working server to which the software license will be attached and assign the service to this server in the requirements explicitly.
Other services are assigned as a single instance.
Cluster services can be reassigned between working servers in the following circumstances:
When a working server is added, partial reassignment of services occurs. Such reassignment is performed automatically.
When a working server is removed from a cluster or becomes unavailable, reassignment of requirement objects processed by the unavailable server is performed. Such reassignment is automatic.
Adding or deleting an infobase from a cluster causes partial reassignment. Such reassignment is automatic.
Reassignment takes place if the cluster administrator applies all or any part of the requirements from the cluster console (see page 111). Assigning working processes
At cluster startup, one working process is launched on each working server, and the system computes the available performance of each working server (see page 37).
The client application connects to the 1C:Enterprise server cluster according to the rules listed below.
The required working server is selected in accordance with the requirements for assigning and the restrictions on RAM use.
Restrictions on RAM use are considered in the case of a query for connection to an infobase to which there are no established connections on the working server selected. If the RAM use limit is exceeded, the working server is excluded from the list if there is another working server that has not exceeded the limit. Working servers that cannot process a required connection according to the requirements for assigning are also excluded.
A list of working processes that are available and can process the connection requested is defined for the server selected. The working process is included in the list of available working processes, when:
○ The maximum number of infobases being processed is not reached for the working process (the Number of infobases per process property of the working server).
○ The maximum number of connections being processed is not reached for such working process (the Number of connections per process property of the working server).
○ The working process is not preparing for automatic restart.
The system will prefer working processes already serving connections of the infobase the connection to which has to be processed. If such a working process does not exist, the system selects a process with a maximum number of connections being served.
If the system fails to select any working process, a new working process is started on the working server to process the requested connection.
When the connection is established by an existing session (if the previous call connection failed to be used once again), the working process that served the previous connection of this session will be selected. Another working process can be also selected if its available performance exceeds the available performance of the current working process by at least 25%.
When 2 working processes exist for 20 minutes on the same working server for which the aggregated number of connections and infobases being served is less than the values specified in the working server properties (Number of connections per process and Number of infobases per process), the process that serves fewer connections will be marked as obsolete and stopped after closing the last connection. Existing connections to an obsolete working process will be "asked to leave" the working server during the next call via the connection. The obsolete working process is ignored when queries for processing new requirement objects are distributed.
When the number of connections processed is calculated, all connections created by the debugger to verify the access rights for debugging are taken into account.
2.1.7.4. Cluster administration examples
The server cluster specified below will be used to analyze sample requirements for assigning functionality.

Fig. 10. Cluster used for sample requirements
The cluster characteristics are as follows:
Number of working servers: 3
Resilience Level: 1
Number of central servers: 2 (SRV1, SRV2)
Operating systems used on working servers:
○ SRV1: Windows ○ SRV2: Linux
○ SRV3: Windows
The cluster serves the following infobases:
DemoDB
WorkDB
WARNING
The examples below are not a complete solution to any problem; they are provided only to demonstrate how to allocate requirement objects among working servers in the cluster.
Assigning all background jobs to a single working server
If you need to assign all background jobs to the SRV1 working server, you should specify the requirements for assigning functionality for SRV1 as listed below:
Requirement object: Client infobase connection.
Requirement Type: Assign.
Infobase name: not to be specified.
Additional parameter value: BackgroundJob.CommonModule. Assigning the licensing service to a dedicated working server
You need to activate a multi-user client license for the computer where the SRV2 working server is running at and assign the licensing service to this computer. In this case specify the following requirement for the SRV2 working server:
Requirement Object: Licensing service
Requirement Type: Assign
Infobase name: not to be specified
Additional parameter value: not to be specified
When activating the software license via the 1C:Enterprise server, specify SRV2 as the name, as otherwise the server cluster will not be able to use the activated license as it will be activated for another computer.
Ban on assigning the external data source access service to a working server
You need to allow the service to use external data sources on the SRV1 and SRV3 working servers and to ban it on the SRV2 working server. To do this, specify the following requirement for the SRV2 working server:
Requirement object: External data sources XMLA access service
Requirement Type: Do not assign
Infobase name: not to be specified
Additional parameter value: not to be specified
One working process serving a single infobase
You need to customize the server cluster in such a way that each infobase is served by just one working process. To do this, set the property Number of infobases per process for each working server to 1.
As a result, two working process will be created on each server (thus 6 in total, 2 working processes for each of 3 working servers). In this case, one infobase will be served by 3 working processes on 3 working servers.
Assigning working servers to process the infobases selected
You need to customize the server cluster in such a way that the DemoDB infobase is processed only by the SRV3 working server, and the WorkDB infobase is processed by both working servers: SRV1 and SRV2. To do this, set up the following rules:
For the SRV3 working server:
○ Requirement Object: Any requirement object
○ Requirement Type: Assign
○ Infobase name: DemoDB
○ Additional parameter value: not to be specified
For SRV1 and SRV2:
○ Requirement Object: Any requirement object
○ Requirement Type: Assign
○ Infobase name: WorkDB
○ Additional parameter value: not to be specified
These rules will distribute all server cluster mechanisms – connections, background jobs, session data services, etc. – among the working servers.
Assigning specific background jobs to a specific working server
You need to customize the server cluster in such a way that only reports are executed on the SRV1 working server, only FullTextSearchUpdateIndex and SalesAggregateUpdate scheduled jobs are executed on the SRV2 working server, and other background jobs are executed on the SRV3 working server. To do this, set up the following rules:
For the SRV1 working server:
○ Requirement:
□ Requirement object: Client infobase connection
□ Requirement Type: Assign
□ Infobase name: not to be specified
□ Additional parameter value: BackgroundJob.Report For the SRV2 working server:
○ Requirement:
□ Requirement object: Client infobase connection
□ Requirement Type: Assign
□ Infobase name: not to be specified
□ Additional parameter value: BackgroundJob.CommonModu- le.WorkWithFullTextSearch.FullTextSearchUpdateIndex ○ Requirement:
□ Requirement object: Client infobase connection
□ Requirement Type: Assign
□ Infobase name: not to be specified
□ Additional parameter value: BackgroundJob.CommonModu- le.ScheduledJobsRorAggregates.SalesAggregateUpdate
2.1.8. Security Profiles
To meet its own needs, the applied solution being executed can use various external resources: file system directories, COM objects (on Windows systems), external components, OS applications, etc. However, for security reasons, various applied solutions can access only a limited subset of external resources. You may need to create a separate directory of temporary files for each area of the split infobase or specify a list of internet resources that the applied solution can access.
To impose such limits, security profiles can be set for the server cluster. A security profile is a set of explicit authorizations for use by certain external resources (with a list of such resources being specified) that can be assigned to infobases registered in the cluster. Security profiles are created by the administrator, and these allow you to set the following authorizations:
authorization to use this profile as a security profile in safe mode – if this authorization is selected (the Can be used as a safe mode security profile profile property), this security profile name can be specified in the 1C:Enterprise script when enabling safe mode and connecting external reports and processors.
available server file system resources (see page 48).
available COM objects (only for servers run under Windows, see page 52).
available add-ins (see page 53).
available external reports and data processors, and the possibility to use the Execute() operator and the Evaluate() function (see page 53).
available OS applications (see page 54).
available internet resources (see page 55).
Authorization to access the privileged mode; if such authorization is set (the Grant full access to: privileged mode profile property), then the privileged mode may be enabled when this profile is used as the profile in safe mode (see page 56).
To enable the infobase to use the security profile created, the name of that profile should be specified in the infobase properties (using administration tools). The name of the profile that will be used to set the safe mode in the applied solution can be specified in the infobase properties.
Some authorizations allow a list of permitted resources to be set. These are:
available resources of the server file system
available COM objects (only for servers run under Windows)
available add-ins
available external reports and data processors
available OS applications
available Internet resources
In this case, the following is applied:
If the checkbox (e.g. access to Internet resources) is unchecked in the security profile, then no Internet resource can be used from the infobase for which this security profile is specified.
If this checkbox is checked in the infobase, then the applied solution has full access to Internet resources.
If only limited access (based on the list) is required, then uncheck the checkbox and set a list of resources for which you wish to allow access.
Let us consider working with specific authorizations in detail.
2.1.8.1. Server File System Resources
Virtual directories are used to access file resources on the server. This implies that the security profile has a virtual file system where system directories are created. Each virtual directory reflects the real file system, subject to certain rules. When the applied solution needs to execute a file operation, the path to the file located in the virtual file system is specified in the relevant function parameter. 1C:Enterprise translates the virtual directory to a real one and generates a real path to the file with which the actual work is carried out. The applied solution cannot receive the information into which physical path the virtual directory will be reflected.
Where multiple virtual directories are specified in the security profile, the applied solution can only access those resources. No attempt can be made to access any other channel (either real, or virtual).
Virtual directories are used to call the 1C:Enterprise script method:
Global Context:
○ BinDir()
○ TempFilesDir()
○ ValueToFile()
○ ValueFromFile()
○ FileCopy()
○ MoveFile()
○ DeletFiles()
○ FindFiles()
○ CreateDirectory()
○ SplitFile()
○ MergeFiles() ○ GetTempFileName() Picture object:
○ File-name-based wizard
○ Write()
BinaryData object:
○ File-name-based wizard
○ Write()
TextExtraction object:
○ GetText()
○ Write()
TextDocument object:
○ Write()
○ Read()
SpreadsheetDocument object:
○ Write()
○ Read()
FormattedDocument object:
○ Write()
GraphicalSchema object:
○ Write()
○ Read()
GeographicalSchema object:
○ Write()
○ Read()
File object:
○ File-name-based wizard
XBase object:
○ File-name-based wizard
○ OpenFile()
○ CreateIndex()
○ CreateFile() XMLReader object: ○ OpenFile()
XMLWriter object:
○ OpenFile()
XMLCanonicalizingWriter object:
○ OpenFile()
XSLTransform object: ○ LoadFromFile()
○ TransformFromFile()
FastInfosetReader object: ○ OpenFile()
FastInfosetWriter object:
○ OpenFile()
ZipFileWriter object:
○ File-name-based wizard
○ Add()
○ Open()
ZipFileReader object:
○ File-name-based wizard
○ Extract()
○ ExtractAll()
○ Open()
ClientCertificateFile object:
○ Wizard by default
CertificationAuthorityCertificatesFile object:
○ Wizard by default
HTMLWriter object:
○ OpenFile()
HTMLReader object: ○ OpenFile()
TextReader object:
○ File-name-based wizard
○ Open()
TextWriter object:
○ File-name-based wizard
○ Open()
CryptoCertificate object:
○ File-name-based wizard
CryptoManger object: ○ Sign()
○ VerifySignature()
○ Encrypt()
○ DrillDown()
○ GetCertificatesFromSignature() DataHashing object: ○ AddFile()
The virtual directory is described with a number of parameters:
A logic URL is an address to be used by the applied solution. This parameter must look like the start of a real path in the relevant file system (for Windows and Linux). The applied solution can only use paths that start with the value specified in this property. It is unique within a single profile.
There are two predefined logic URLs used by system methods:
○ /bin is a loading modules directory of the current 1C:Enterprise version. This virtual directory is used by the BinDir() method.
○ /temp is a temporary file directory. This virtual directory is used by the TempFilesDir() method.
The physical URL is an address indicating the physical location of the logic URL in the server file system. It can include special substitution characters. When executing the file operation, 1C:Enterprise converts the logic URL into a real address of the file system by replacing all substitution characters. Next, every sequence of characters inadmissible in the URL is replaced with the character.
CAUTION!
In general, the applied solution should trace the existence of the physical reflection of the virtual directory.
The substitution characters that can be used in the address are as follows:
○ %r – infobase reference name;
○ %i – infobase identifier;
○ %z – string presentation of current values of current session separators in the format accepted for the /Z command string parameter.
○ %s – session number;
○ %c – connection number;
○ %p – identifier of the safe mode of the application code execution;
○ %e – directory of 1C:Enterprise loading modules;
○ %t – current directory of the temporary files of the operating system;
○ %u – directory of the current user’s application data;
○ %u – directory of all current users’ application data; ○ %r – name of the current infobase user; ○ %% – % character.
Data reading is allowed – the check box determines whether or not the reading of files from this virtual directory is allowed.
Data writing is allowed – the check box determines whether or not the writing of files in this virtual directory is allowed.
When physically specifying the URL, you can specify both directories of the computer with 1C:Enterprise, and network resource. In this case, you must take into account special aspects of the file system organization and of interaction with network resources of the operating system that runs the server.
When the session is terminated, any physical directories defined with the %s substitution character are deleted. Similarly, when the connection ends, any physical directories defined with the %c substitution character are deleted. Entering the safe mode for the code execution in the 1C:Enterprise script has its own unique identifier. When the safe mode is closed, any physical directories defined with the %p substitution character are deleted.
2.1.8.2. COM Objects of the Server
The security profile of the cluster can contain a list of classes of COM objects that may be used in the applied solution.
IMPORTANT!
This option is available only for servers running in Windows.
If the infobase references a security profile where COM object use is restricted, then only COM object classes included in the list of COM object classes allowed for this profile can be used. The COM object used by the configuration corresponds to the item on the security profile list of permitted COM objects, provided that the value of the COM object computer property is congruent and the non-null values of the File (moniker) and COM class ID properties match. Any attempt to create an instance of any COM object not presented in the list returns an exception. The allowed class of the COM object is described with the following parameters:
name – a unique name of the COM object class. It is unique within a single profile.
file (moniker) – a file moniker name. It is used when the GetCOMObject() method is called with no value of the COMClassName parameter specified. For details on the file moniker see: http://msdn.microsoft.com/en-US/library/windows/ desktop/ms688670(v=vs.85).aspx.
COM Class Identifier – a string that is a COM object class identifier in the format of the Windows registry without curly brackets. This value is used in the new COM object wizard and in the GetCOMObject() method.
COM Object Computer – computer on which a COM object can be created. It is used by the new COM object wizard. To specify the current computer, the localhost string should be used, and the empty string means that the COM object can be created on any computer.
2.1.8.3. Add-ins
The security profile of the cluster can contain a list of add-ins that can be used in the applied solution. If the infobase references a security profile where the use of add-ins is restricted, then only external components included in the list of add-ins allowed for this profile can be used. Any attempt to execute the AttachAddIn() method for a component not included in the list returns an exception. An empty list means that this profile does not permit the use of any external components.
The allowed add-in is defined using the following parameters:
name – a unique name of the add-in. It is unique within a single profile.
checksum – a SHA1 checksum of the allowed add-in converted to the base64 format.
To build up the checksum, the DataHashing object and the Base64String() method of the global context can be used.
2.1.8.4. External Reports and Data Processors
The cluster security profile can contain a list of external reports and processors that can be used from the applied solution code without enabling the safe mode. If the infobase references a security profile where the use of external reports and processors is restricted, then only those external reports and processors that are included in such a list can be used without enabling the safe mode. Any attempt to use external reports and processors that are not included in such a list without enabling the safe mode results in an exception. An empty list means that this profile does not allow the use of any external reports and processors with the safe mode disabled. This profile element also allows you to manage the option for using the Execute() operator and the Evaluate() function in the safe mode. If the Grant full access to: external reports and data processors property of the security profile is unchecked, then the Execute() operator and the Evaluate() function can be executed in the applied solution only if the safe mode is enabled (by specifying it explicitly before using the operator or the function). If the applied solution uses the Execute() operator and the Evaluate() function for technological purpose (in the unsafe mode), you cannot use the security profile with the Grant full access to: external reports and data processors property unchecked for such applied solution. The allowed external report or processor is defined using the following parameters:
Name – a unique name of the external report or processor. It is unique within a single profile.
checksum – a SHA1 checksum of the allowed external report or processor converted to the base64 format.
To build up the checksum, DataHashing object and Base64String() method of the global context can be used.
2.1.8.5. Operating System Applications
The security profile of the cluster can contain a list of applications that can be run from the applied solution. If the infobase references a security profile where the running of applications is restricted, then only applications (executable files) included in the list of allowed applications of this profile can be used. An attempt to execute the RunApp() method with an application or parameters that do not correspond with any record in the list will return an exception. An empty list means that this profile does not allow any applications to be used.
Parameters used to define allowed operating system applications are as follows:
name – a name of the application. It is unique within the security profile.
run string template – an application run string template. It consists of a sequence of template words separated by spaces. The template word is an arbitrary sequence of characters and can contain substitution characters. If a template word contains spaces, it should be enclosed in quotation marks.
Substitution characters are as follows:
○ % – an arbitrary sequence of characters;
○ _ – one arbitrary character;
○ * – a file name. If the template word begins with the * character, the parameter is a path to the virtual directory. Before the execution, the virtual directory is replaced with the physical one.
○ \ – a character prefix. Specifying this character before the template word makes that word a non-template one.
Verification of whether the application to be run conforms with the list of allowed applications is performed for the name of the application to be launched and for each of the parameters in the run command. The absence of the matching template word means that the template does not correspond to the startup line.
For example, the xcopy */temp/% */usrappdata/% template allows you to copy an arbitrary file from the /temp virtual directory to the /userdata virtual directory.
Parameters in the startup line are separated by one or more spaces.
A string enclosed with quotation marks (") is one parameter. A sequence of words where the first and the last words contain an uneven number of single quotation marks is considered as one parameter. Where there is a first word in quotation marks but there is no second word, the content up to the end of the string constitutes one parameter. If the parameter is not enclosed in quotation marks, the quotation mark is represented by a couple of characters: \". The quotation mark within the parameter enclosed within quotation marks can be represented by one of these character pairs: \" or "".
2.1.8.6. Internet Resources
The security profile can contain a list of internet resources that can be called from the server code of the applied solution. If internet use is restricted in the security profile, then the use of the InternetConnection object is not allowed, and the InternetMail, HTTPConnectionå, FTPConnection, WSÎDefinitions objects can be used to call only those resources that are included in the list of internet resources allowed for that profile. When other resources are called, an exception will be generated. An empty list means that none of the internet resources can be called.
The allowed internet resource is described with the following parameters:
name – the resource name for its identification. It is unique within the security profile.
address – the resource address without any indication of protocol.
port – the number of the port used to interact with the specified resource.
resource type (protocol) – the protocol used to interact with the specified resource. Protocols that can be specified (the character case makes no difference) are as follows:
○ imap – IMAP e-mail server.
○ pop3 – POP3 e-mail server.
○ pop3 – SMTP e-mail server.
○ http – web server.
○ https – safe web server connection.
○ ftp – ftp server.
○ https – safe ftp server connection.
2.1.8.7. Privileged Mode
If this authorization is set, then you can enable the privileged mode when using that profile as a safe mode profile. In this event, access to various external resources is determined by parameters of the set security profile.
2.1.9. Server Cluster Security
When 1C:Enterprise operates in the client/server mode, data security is provided by ensuring that 1C:Enterprise data are only accessed using 1C:Enterprise tools. In this context, we can define several areas of security provision.

Fig. 11. General security chart
All the client applications and external connections use the 1C:Enterprise data only via the 1C:Enterprise server cluster after the 1C:Enterprise authentication procedure. This procedure involves the application providing the server cluster with its 1C:Enterprise user name and password before it can begin working with the cluster. Further work with the server cluster will only be possible if the user with the corresponding password is registered in the infobase.
The data that the 1C:Enterprise server cluster works with are divided into the infobase and service data. The server cluster is therefore responsible for ensuring data security in the following areas (for numbering of the areas, see fig. 11):
during exchanges between the client and server cluster (1),
during exchanges between the server cluster console and cluster (2),
during data exchanges between server cluster and web server (7),
when storing service data in the server cluster (3), during data exchange within the cluster (4).
The infobase is stored in a database, and its security as well as security during exchanges between the server cluster and the database server are ensured by the tools of the DBMS used (5).
When an infobase is connected to via a web server, security of data exchange between the client application and the web server is ensured by the web server used (6).
2.1.9.1. Security of Data Transferred between a Client and a Server Cluster
Security of data transferred between a client and a server cluster is ensured by the capability of encrypting the data. You can select one of the three security levels:
disabled
connection only
continuouosly
The disabled level features the lowest security while continouosly is the most secure one. RSA and Triple DES encryption algorithms are used for secure TCP/IP connection.
"continouosly" Security Level
The continouosly security level provides comprehensive protection of the data flow (both passwords and the data) between the client and the server cluster.
IMPORTANT!
Please note that there can be a considerable system performance slowdown with this security level.
The client and server cluster interaction protocol is outlined below:

Fig. 12. "continouosly" security level
The interaction protocol is the same both for the cluster manager (rmngr) and for the working process (phost): once the connection is established, the first data exchange procedure is RSA encrypted while subsequent data exchanges use Triple DES encryption.
The security level is defined when an infobase is created. This information is stored both on the client (in the infobase list), and on the server cluster (in the server registry). You cannot change the security level of an infobase after it has been created. The client application can, however, request that the security level be increased. It is for this reason that when a connection is established, the client generates a private and a public RSA keys, and sends the public key and security level specified on the client for this infobase to the server cluster. This is the desired security level.
The server cluster selects the strictest security level from among those sent by the client and specified for the infobase in the cluster registry. This is the actual security level. Besides, the server cluster generates a session key for Triple DES encryption, and sends it to the client together with the actual security level after encrypting this data using the client's public key.
Subsequent data exchanges use the actual security level. At that, both the client and the server encrypt the transferred data using Triple DES session key. "connection only" Security Level
The connection only security level provides partial protection of the data flow (passwords only) between the client and the server cluster. This security level is a trade-off between security and performance.
On the one hand, infobase data are exposed during transmission. As these data represent the largest portion of all the data transferred, system performance is virtually not damaged.
On the other hand, critical information (passwords) is always encrypted prior to transmission. As a result, if this data flow is intercepted, the hacker will only get a negligible part of the infobase data. As password information remains inaccessible, the illegal intruder will not be able to authenticate themselves in the infobase, access other data, or perform any actions on the infobase.
The client and server cluster interaction protocol is outlined in fig. 13.
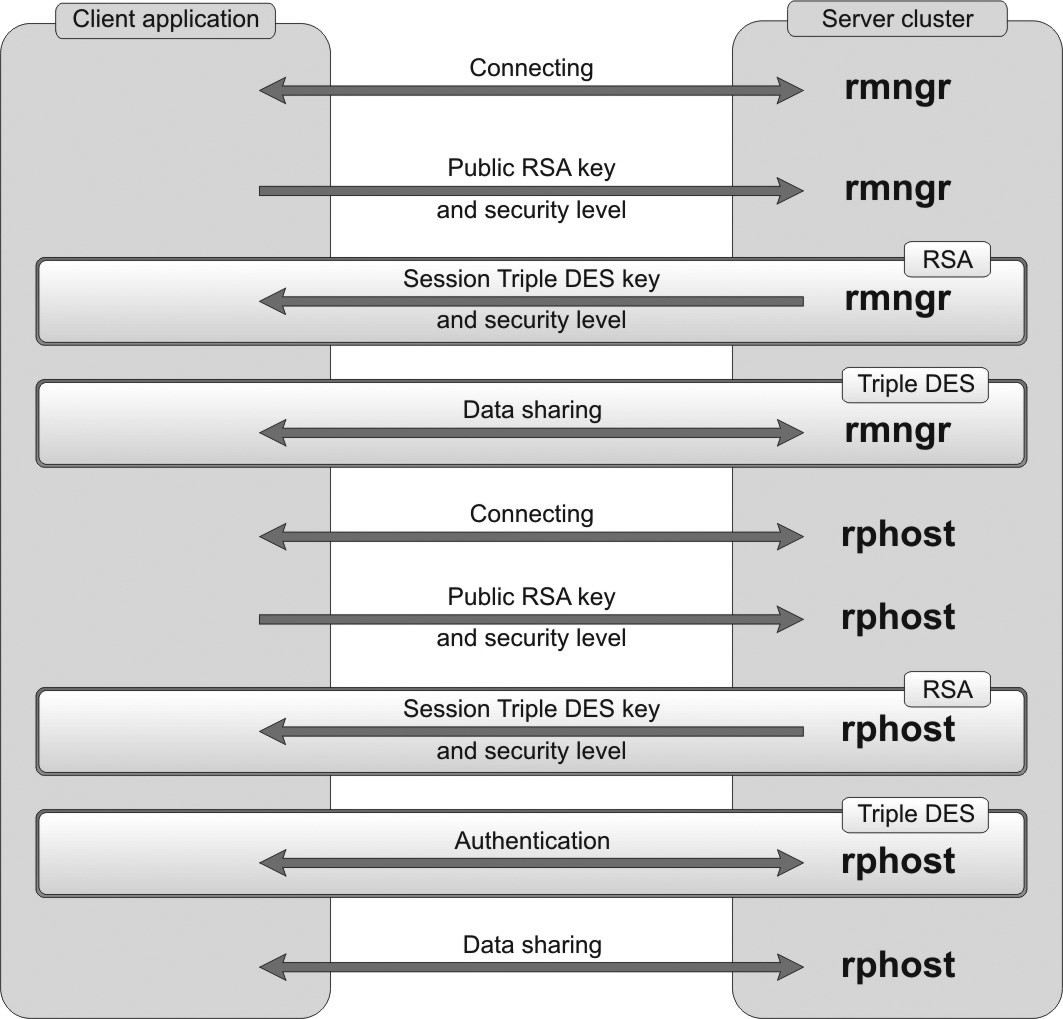
Fig. 13. "connection only" security level
Once the connection is established, the first data exchange procedure is RSA encrypted while subsequent data exchanges use Triple DES encryption until the authentication procedure is completed. Subsequent data exchanges are not encrypted.
"disabled" Security Level
disabled security level is the least strict but it features the best performance. Virtually all the data are sent unencrypted.
The client and server cluster interaction protocol is outlined below:
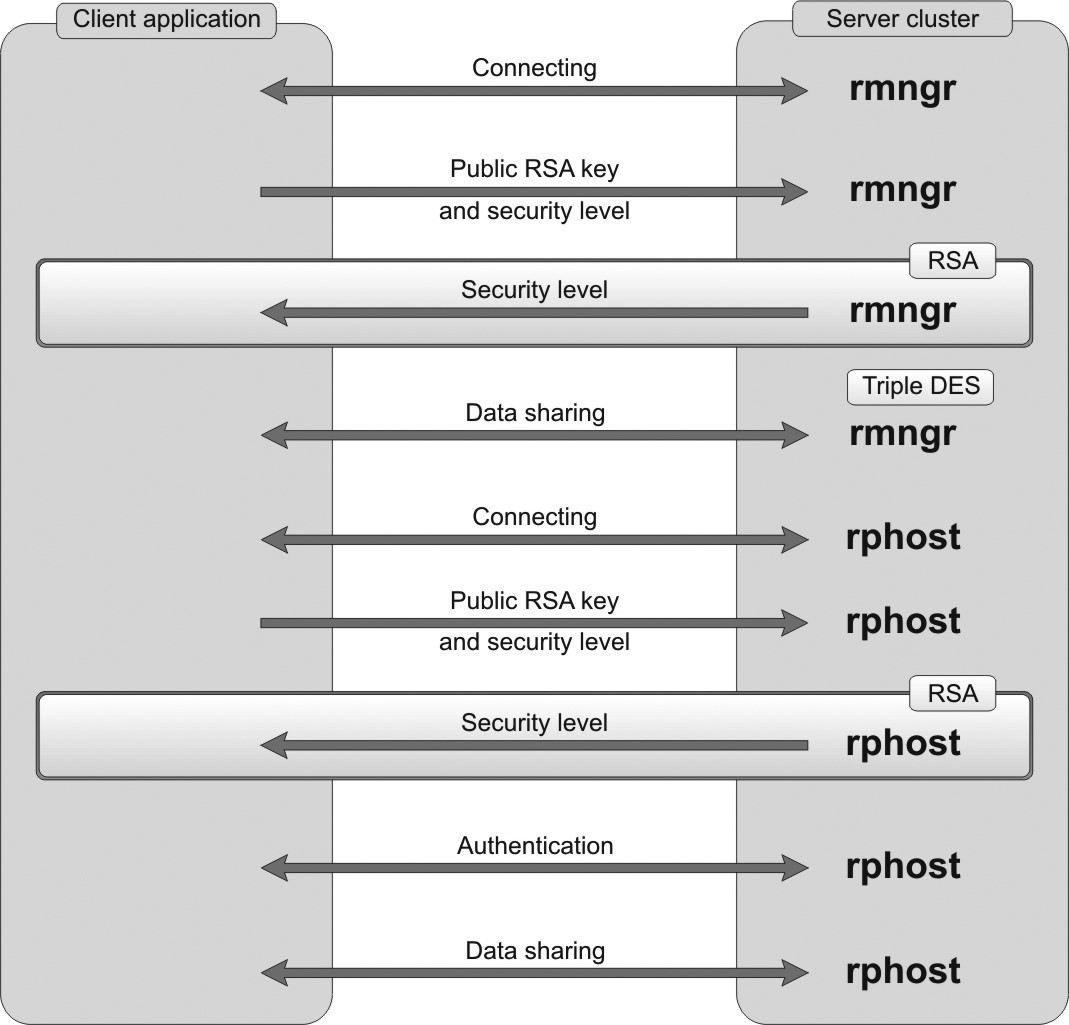
Fig. 14. "Off" security level
Once the connection is established, the first data exchange procedure is RSA encrypted. Subsequent data exchanges are not encrypted.
If the client application and the server cluster are located on the same computer and the security level is set to disabled, the data they exchange are sent unencrypted.
2.1.9.2. Security of Data Transferred Between a Server Cluster Console and the Server Cluster
The security of data transferred between a server cluster console and the server cluster is also ensured by the capability of encrypting the data transferred. The same three security levels are used: disabled, connection only, and continuously.
The server cluster console interacts with the server agent (ragent process). The required security level is defined on server agent startup. The actual security level is selected by the server agent. The server agent selects the strictest security level among the one specified on startup and the levels of all the clusters located on this central server. The cluster security level is defined when the cluster is created (by software or interactively).
2.1.9.3. Security of Data Stored in the Server Cluster
A server cluster uses some service data, including a list of server clusters, cluster registries, etc. Service data is a set of files stored in two directories:
application data directory
temporary files directory
The principle of working with the service data is based on the idea that only the cluster manager (rmngr) and the server agent (ragent) can access the server cluster service data. Working processes (phost) only use service data via the cluster manager, as they are potentially dangerous because configuration code fragments can run in such processes.
Security of the Application Data Directory
During the 1C:Enterprise server cluster installation procedure, a dedicated directory is created in the application data directory that is intended strictly for the 1C:Enterprise server cluster files (see fig. 15).
Full rights for this directory are granted to the user account USR1CV8 that runs the server agent by default. Other users are denied access to this directory. The server agent starts the cluster manager under the same user account it runs under itself.
The following rights are available to the user USR1CV8:
Log on as a service
Log on as a batch job
The USER1CV8 user must belong to the following groups:
Performance Log Users.

Fig. 15. Application data directory
Working processes are also started by the server agent. A working process is started by default under the same user account that starts the server agent. However, it is possible to create an additional operating system user account that will run working processes only. This helps prevent direct access of configuration program code to service data.
For a working process to be launched not under the user account the server agent runs under, swpuser.ini can be located in the application data directory for the server agent user (see "1C:Enterprise 8.3. Administrator Guide"). Security of the Temporary Files Directory
Temporary files data is protected in a different manner. As the system directory of temporary files is a shared directory, the access rights for every temporary file are granted separately.
When a temporary file is created by the 1C:Enterprise server cluster, the USR1CV8 user is granted full rights to the created file. Other users are denied access to this file. This means that all the data stored in temporary files are protected from unauthorized access.
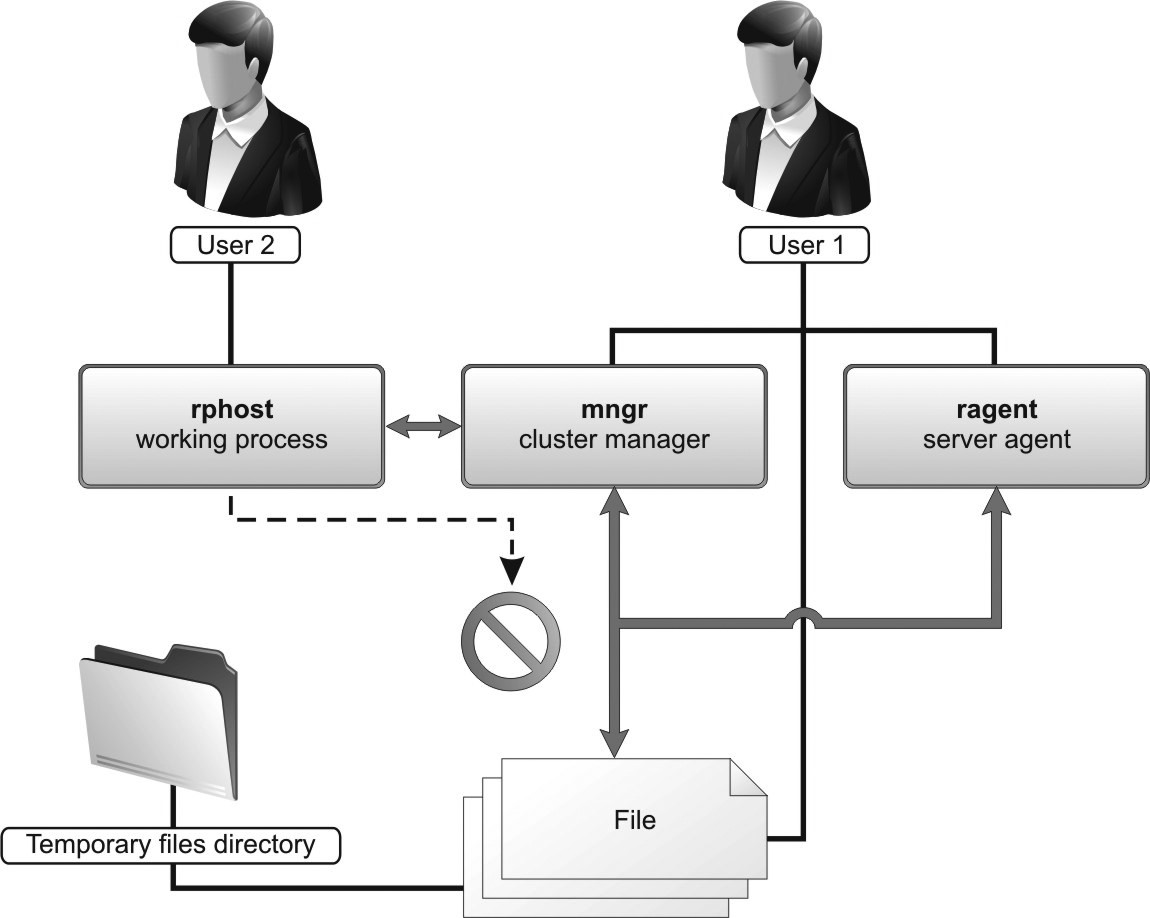
Fig. 16. Access restriction
Encryption of Passwords Stored in Server Cluster Service Data
Server cluster administrator passwords and infobase access passwords are encrypted and stored in the server cluster. SHA1 and AES128 algorithms are used for encryption.
SHA1: used to encrypt passwords verified by 1C:Enterprise (e.g., cluster administrator password, central server administrator password). The source text of the stored passwords cannot be restored: it is only possible to verify if the checksum of the entered password matches the stored checksum.
AES128: used to encrypt passwords requiring restoration of the source text (e.g. DBMS access passwords).
2.1.9.4. Security of Data Transferred within a Server Cluster
The security of data transferred within a server cluster (e.g. between working processes and the cluster manager) is provided for by the capability of encrypting the data transferred. The same three security levels described above are used: disabled, connection only, and continouosly.
The cluster security level is used for interaction between a working process and the cluster manager. The security level for interaction between the server agent and cluster manager is the strictest level selected among the one used for server agent startup and that of the cluster served by this manager.
2.1.9.5. Security of Data Transferred between a Server Cluster and DBMS
The channel between a server cluster and the DBMS is secured by means of the DBMS used. All the supported database management systems allow for configuration of their client components located in a cluster to encrypt the traffic between the components and the DBMS itself. All the supported database management systems can operate via SSL.
2.1.9.6. Security of Data Transferred between Client Applications and a Web Server
SSL or TLS encryption protocols are used to secure the channel between a web client and the web server or between a thin client and the web server.
These protocols are enabled by HTTPS connection with the web server.
This requires that a valid server certificate is available on the server. This certificate guarantees to the client that the public key of the server used for data encryption is authentic.
Client certificates confirming the client authenticity to the server can be also used.
You should consider restrictions related to the operating system under which the application is run: the client application under Linux does not support client certificates from the Windows certificate store.
2.1.9.7. Security of Data Transferred between a Web Server and a Server Cluster
Security of channels between the server cluster and the web server is ensured by data encryption algorithms available in 1C:Enterprise: RSA and Triple DES.
Connection between a cluster and a web server is protected by the cluster only based on the properties of the infobase that is connected to (for details, see page 48).
2.1.9.8. Central Server and Cluster Administrators
1C:Enterprise server cluster can be administrated both with and without administrator authentication.
If authentication is not used, any user connected to the cluster central server can carry out all the administration activities both on the central server and on any cluster on this server. By default, administrator authentication is disabled when a 1C:Enterprise server cluster is installed.
To restrict the number of users that can carry out administrative activities, you can create separate lists of administrators for the central server (see page 116) and for every cluster (see page 134) on this server. The areas of control of central server administrators and cluster administrators do not overlap.
Being authenticated as the central server administrator allows a user to execute administrative tasks on the central server. However, to perform any administrative activities on a specific cluster the user should be authenticated as administrator of this cluster. At the same time, to run any administrative procedures on a cluster, the user must be authenticated as cluster administrator; additional authentication as the server administrator is not required.
The central server/cluster administrator authentication is enabled automatically as soon as at least one administrator is created in the central server/cluster administrators list.
If authentication is enabled, any user who is not authenticated as the central server administrator can only view and modify the parameters for connection to the central server in the server cluster administration console.
Any user who is not authenticated as the cluster administrator can only view cluster properties. These users can also create objects of a cluster, an infobase, etc. using the 1C:Enterprise script, but are unable to register these objects in the cluster.
2.1.10. Infobase Locks
To ensure consistent interaction with an infobase, 1C:Enterprise relies on a locking mechanism that provides for competitive work with the following three components:
configuration
infobase
database
The mechanism principle is described in the section covering the server cluster administration utility (see page 111).
There are two types of locks: shared and exclusive. Shared locks support concurrent operation of multiple sessions. The exclusive lock is used when you need to prevent data being changed by other sessions.
As far as system administration is concerned, it is important to understand when the exclusive lock is enabled (exclusive mode). In some situations the exclusive lock for a configuration and an infobase is enabled and disabled by the system automatically (see below). The exclusive lock for the database may be enabled or disabled both automatically by the system and manually by the developer by calling the SetExclusiveMode() script method.
Please note that these locks are 1C:Enterprise tools responsible for access to the database. Thus, for example, enabling the exclusive lock for a database will not prevent access to the database by other applications that do not rely on 1C:Enterprise mechanisms when interacting with the database.
Exclusive lock:
of a configuration is enabled by the system when Designer is launched and ensures that multiple Designers will not be connected to the same infobase.
of an infobase means that only one session of any type can exist. The lock is enabled:
○ when the database configuration is updated
○ when the infobase is restored ○ when the infobase is dumped
○ when an initial infobase image is created
○ when the infobase is converted for a new platform version
○ during test and repair procedures
of a database means that only one Designer session can exist accompanied by one additional arbitrary session. The lock is enabled:
○ When the SetExclusiveMode()method is executed. It is required when consistent database changes are necessary but cannot be executed in the same transaction. For example, when objects are deleted from a large infobase in batches.
○ When documents are posted in batch (only for the thick client).
If infobase service connections exist while you are trying to switch to exclusive mode, these connections will not prevent you from enabling exclusive access mode (both to the infobase and to the database).
Since the session defines an active user, sessions will prevent switching to the exclusive mode (excluding a cluster console session). In addition, when the exclusive mode is attempted, all infobase connections with no sessions assigned will be broken implicitly. If the exclusive mode is enabled for infobase or database access, no new sessions can be initiated.
If there are web servers connected to this infobase, attempting exclusive access will result in requests sent to these servers to clear the connections pool.
2.1.11. Working Process Load Statistics
For every working process, the server cluster calculates a set of parameters that describe the working process load. All these parameters are calculated for a period of approximately 10 minutes:
Average server cluster response time;
Average time spent by server cluster;
Average time spent by DBMS;
Average time spent by client;
Average time spent by lock manager; Average number of client threads.
The average server cluster response time is the time spent by the server cluster to service one client connection. This time is made up of four components:
The time spent by a working process;
The time spent by DBMS;
The time spent by the client itself (if control was returned back to the client); The time spent by lock manager.
A working process services every client connection in a separate thread. So, at a certain moment, a working process can run multiple client threads. The number of such threads is usually lower than the number of connections (because not all the connections are permanently active). The average number of client threads indicates the average number of threads executed by the server simultaneously calculated for the period of 24 hours.
2.1.12. Location of Cluster Manager Service Files
If you decide to run 1C:Enterprise server as a service during 1C:Enterprise installation, the server agent is launched during the installation process. At that, the service will be run under the user account selected in the system installation dialog but the server cluster service files will be located at <1C:Enterprise installation directory>\srvinfo (service parameters will expressly specify -d startup option).
If you decide to install the server as an application during 1C:Enterprise installation, the server agent is not launched during installation. Once installation is complete, you will need to run the server agent manually. If the -d startup option is omitted, the server cluster service files will be located in the default directory: %USERPROFILE%\Local Settings\Application Data\1C\1Cv8 (%LOCALAPPDATA%\1C\1Cv8 for Windows Vista and above).
IMPORTANT!
If a cluster has already been created on the central server, when you change server agent startup version (as a service or as an application) or the user account the server agent runs under, you should always verify that the specified path to the directory of server cluster service files is correct. If upon startup the server agent cannot locate the list of clusters, it will create a new cluster on the server.
In Linux, the service files of the server cluster will be located in the /home/ usr1cv8/.1cv8/1C/1cv8 folder (or a short version: ~/.1cv8/1C/1cv8).
2.2. SPECIFICS OF OPERATION UNDER LINUX OS
When 1C:Enterprise server cluster works on Linux machines, the following limitations apply:
A working process of the 1C:Enterprise server cluster cannot interact with Microsoft SQL Server database management system.
A working process of the 1C:Enterprise server cluster cannot interact with COM objects. Compiling server modules working with COM objects is allowed, but an attempt to run such a module will result in an error message.
Kerberos authentication (the Windows-based version supports the NTLM protocol, which enables authentication without PDC, among others) and/or authentication with a user name and password is allowed.
The InternetConnection object functionality is not available.
To be able to use certain features, the 1C:Enterprise server running under Linux should have some libraries available. For the list of the required libraries and the features that need such libraries, see page 14.