
Abstract
As domain-specific software becomes more available, businesses face a dilemma: whether to acquire commercial off-the-shelf (COTS) enterprise management systems or to build them in-house. Companies choosing to create a product internally are often rewarded with flexibility and control over their development process and its results. However, when expanding, they can outgrow their ability to support the developed software.
Part 1.
5 Protracted In-House Development
This section describes my personal experience in Si-Trans during 2010–2011, as shown in Figure 5. By that time, the internal system did not work acceptably, and the management was exploring an opportunity to cut the technical debt.

Figure 5: The timeline: 1995–2010. My experience at Si-Trans.
5.1 Accumulated Technical Debt
I joined Si-Trans in 2010 as a software developer. I had two main responsibilities: to develop the old information system, which was almost 15 years old at that time, and to prototype a new one. Priorities between these two activities were not specified up-front. Looking back now, I ended up spending much more time on the old system.
The relatively wide spectrum of duties allowed me to communicate with different departments of Si-Trans and find out the details that this practicum is based on. At the time I got familiar with the state of the in-house development in Si-Trans, a number of technical issues revealed themselves:
• Unmanageable source code: the internal system’s code had grown unsuitable for reading, understanding the high-level intent, and business logic extraction. This was true due to the increased size, approximately 300 KLOC including comments, and because the structure of code modules was plain. If a developer tried to comprehend the source code organization, he faced many same-level entities that interacted in many subtle ways. Even by the end of my employment at Si-Trans, I could still hardly understand the role of half of the code modules without scrutinizing them.
• An eroded database schema: After years of carelessly managed evolution of the database, many tables and fields were obsolete or used in ways that nobody remembered. Several tables captured similar concepts—e.g. city, office, and warehouse—and needed many-to-many mappings between each other because redesigning in a better way would take too much effort. One particularly poor table contained transportations data: it had over 100 fields and over 30 thousand records, which followed different semantic assumptions about fields. To my knowledge, there was no single person in the company who understood what each field in this table meant.
• Low performance: the system did not meet end users’ performance needs. As the number of users grew to about 160 in 2010, the database became a performance bottleneck. This issue introduced noticeable waits for the users. It was not possible to sufficiently speed up the operation under the constraints of the thick-client architecture.
• Poor runtime stability: subtle implementation bugs did not get sufficient treatment for long periods of time. The toughest problems arose from conceptual mismatches between parts of the system. One example was different assumptions about currency cross rates in financial transactions. Some parts of the code treated it as just a derivative of individual currency rates. At the same time, there existed code that treated a cross rate as an independent characteristic of a transaction and, thus, violated the assumption of the former code. Such semantic mismatches led to corrupting database tables and crashing all thick clients companywide.
• Insufficient computing environment flexibility: the internal system could be deployed on a small variety of hosts. Thick clients could plausibly run only on Windows-based machines with a high bandwidth and a stable Internet connection because they sent relatively big queries and datasets over network. Si-Trans management wanted to deploy the system at warehouses in China to enable more precise tracking of containers with goods, but it was not possible since only an intermittent and low-bandwidth Internet connection was available at the warehouses.
• Difficulties with updating thick clients: our software engineering team could not find an appropriate technical solution for updating thick clients. It needed to be a compromise between shutting down all clients immediately as soon as the update was available and letting clients run as much as they want. Therefore, it was often the case that users were distracted by non-critical updates; also, many users missed critical updates and sometimes corrupted the database, making it incompatible with the newer version of clients.
So, by 2006 the architecture and the codebase did not meet Si-Trans’ requirements. Apart from the technical trouble, I observed the weak management practices of Si-Trans’ top executives that are exemplified in the next subsection.
5.2 Management Style
Top management of Si-Trans was a central point of control for all branches of the company: operations, accounting, legal support, and so on. The software engineering team reported directly to top management as well. I was very uncomfortable with their practices: top management was inconsistent, chaotic, and noncommittal, just as described in Section 3.4.
Two concrete scenarios that I personally witnessed depict the general style of management. These scenarios exemplify how flawed the interaction of management and engineering was at Si-Trans.
Management practices scenario 1: undocumented conflicting patches.
Outset
Half an hour before a work day ends, a top manager shows up in person at the programmers’ office and requests that one feature be implemented before the end of the day. The feature is highlighting all transports that have been stuck at customs for more than 10 days. The motivation for the urgency is that branches in China start daily operation earlier and would like to use the functionality to detect late transports the next day.
Events
The feature is quickly implemented as a complicated condition in thick clients that infers how much time a transport spent at customs from its other attributes. Then an update is distributed among locations before the end of the day.
This business rule about highlighting transports was not documented anywhere except the code. Several weeks pass, and the knowledge about the rule’s existence and location in code leaves the heads of software developers.
The manager who remembers that piece of business logic turns up and asks a different developer to change the condition to 15 days based on the feedback from other employees. Not having time to elaborate on his request, the manager leaves the engineers’ office.
This time, the engineers decide to approach a problem in a more principled way and define a database field “late” for transport. The attribute is populated by a database trigger, and highlighting is implemented based on this new field. The original rule remains in the code because nobody remembered about it, nor could anyone find it quickly enough to remove.
Outcome
Inconsistent display of transport status confuses users. The development team later spends days to find the root of this inconsistency and remove the first implementation that was based on a condition in clients.
Management practices scenario 2: conceptual mismatch.
Outset
A top manager has a very specific GUI in mind and wants it implemented as soon as possible. The GUI will allow users to see and edit the chain of cities through which a transportation goes. No time is given to developers to realize the global impact of this particular GUI on the system.
Events
The GUI and the corresponding data model are implemented and deployed as quickly as it was possible.
Several weeks pass, and users attach chains of cities to a number of transportations.
After the GUI has been implemented, it turns out that it has a conceptual mismatch with the system: it should have used the concept of “branch” instead of the “city”. The initial intent of the GUI was to provide traceability about which branch participated in handling which transportation. This analysis is impossible when chains of cities, not branches, are recorded.
Outcome
Programmers spend a lot of time to spot all code that has been written under the incorrect assumption, to change it, and to convert the data in the database.
Being under constant time pressure, programmers leave bugs behind.
5.3 Reimplementation Effort
I was hired to help reimplement the old information system in a new architecture, labeled V2.0. The new architecture introduced a middle tier between clients and data storage. The middle tier would receive requests from clients, translate them into database queries, apply business rules, and return results to clients. The clients were supposed to become thinner because they did much less computing and they were independent from the database schema. The new architecture aimed to remove the performance bottleneck at the database and simplify the update procedure. A new data model was expected to use the insights obtained over 15 years and to get rid of obsolete parts. Also, there was an intent to develop the new system in a more disciplined way that would include strict coding conventions, design documentation external to code, automated testing, and traceability of requirements to code.
Another decision was to build the new information system with a modern user interface framework— Qt 4. It was more powerful than C++ Builder in two aspects: (a) Qt 4 offered a higher level of abstraction in day-to-day programming activities, with many convenience classes and syntactic sugar; (b) Qt 4 allowed a higher level of reuse for UI parts and behavior. Using Qt 4 promised higher development speed, fewer bugs, and the integrity of user experience.
After one year, our team finished a prototype with only a small part of the functionality of the original system—creating, displaying, and marking containers with goods. We devoted all our remaining time to supporting and extending the old system according to the management’s requests. Shortly after I left Si-Trans, top management stopped allocating resources to the reimplementation, despite the eagerness of the software development team.
5.4 Interpretation: Peak of Technical Debt
The technical issues described in this section came about, I believe, for two immediate reasons:
• The thick client architecture stopped meeting the changing requirements: the architecture could not support needed performance, stability, and easiness of updates because it was overly database-centric and, at the same time, placed too much responsibility on client applications. An enormous technical debt separated this architecture from the requirements, and this gap was impossible to bridge in 2010 by just putting more time into the old system. A complete redesign was needed.
• The source code evolved into a big ball of mud [8]: the codebase was a mess of low-level memory management, business logic, network communication, database queries, user interaction, workarounds of “bugs with design-level significance”, outdated or just dead instructions, and irrelevant comments. It was hard to extract the design intent from the source code, and even harder to modify it without introducing an implicit inconsistency with other parts of code.
The root cause of these two technical concerns was the management style of Si-Trans’ top management. Not only did this style accelerate the accumulation of technical debt, as shown in the examples, but it also caused the company to miss the opportunity to adopt COTS when the in-house system became obsolete. In my opinion, this style’s fundamental problem was too much control and flexibility of the organic development process. The mere existence of programmers placed an obligation on managers to “keep them occupied” no matter what. Active involvement of the managers who did not possess much skill or knowledge about software development was very harmful for the project because they had absolute power to alter any requirements and control the developers. In other words, I believe that the mentality of “we pay them—they do whatever we want” was a source of the most trouble for Si-Trans’ homegrown software.
One might argue that the absence of a software architecture-centric development process could have been the primary reason for the project’s failure. I cannot agree with this statement for two reasons. First, software architecture is just a way to succeed, not the way. Si-Trans’ in-house development would have fared well even without paying explicit attention to architectural design and documentation. The same, if not better, effect could have been achieved by merely letting the team invest more time into maintaining internal consistency of the original system or into the reimplementation later on. Second, I do not see how an architectural process could have been successfully set up in Si-Trans. Any such process would have required continuous investment into “invisible” aspects, as perceived by managers, which was not acceptable to them. Instead, they would have just forced implementing their “brilliant” ideas, which came to them at a high rate. So, it was not the lack of any particular process that made the development fail, but the disruptive behavior of top management.
The relationship between the major concepts of this practicum is shown in Figure 6. The chaotic management style led both to accumulating technical debt and sustaining an in-house development longer than needed. At the same time, the in-house development paradigm let the managers do whatever they wanted. Adapting the 1C COTS could have been a well-fit decision to break this vicious circle.
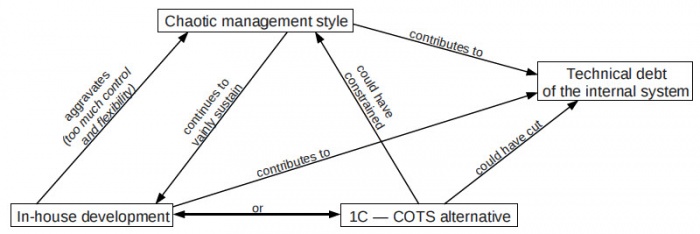
Figure 6: Interrelation of concepts for the buy or build question of Si-Trans.
The reimplementation effort aimed at the most serious issues of the old system. The more suitable 3-tier architecture of V2.0 could provide appropriate performance and reliability. The fact that a disciplined development started from scratch would mean that the problems of technical debt would not bother Si-Trans for at least several years. Additionally, the Qt 4 technology would have saved plenty of development efforts in the long run; also, Qt 4 could have had a positive effect on the usability because of potential reuse of UI artifacts.
In spite of all the advantages of V2.0, it did not go as far as it was expected to. The problem was that the implementation rate for the new information system was low since the old system sucked a lot of time from all programmers. They were not only distracted by fixing bugs in the old system, but also top management kept requesting new features there. Managers were not able to stop extending—not merely maintaining—the old one, even though the software team proposed that many times. So again, a non-optimal strategy of the management intervened. The developers could not keep actively extending both systems at the same time, so the progress on V2.0 was too slow. It was obvious for both programmers and managers that it would take years to implement all functionality of the old system in V2.0. That’s why top management lost their faith in V2.0.
5.4.1 Perspective of the Developers on COTS
One might think that the Si-Trans software developers were responsible for missing the opportunity to adopt 1C. This argument is supported by the fact that technical expertise is needed to point out a suitable COTS option. However, the developers never had an opportunity to do a COTS suitability analysis because they had been overburdened by management feature requests. And, of course, they had never received a request to evaluate COTS alternatives.
From the programmers’ point of view, the 1C platform was too constrained and rigid to be adapted to the management’s requirements. Moreover, it gave too much support to programming by eliminating technical challenges like memory management, which “made programming fun”. 1C also featured a domain specific language with Cyrillic alphabet, writing in which was too much of a cultural shock for software engineers who were conventionally trained in C++ and Java. Finally, some engineers believed that 1C’s promises of scalable architecture and suitability of the ready-todeploy components were exaggerations .
So, the Si-Trans development team did not sincerely consider 1C worthy of closer analysis. The developers constantly informed the management of the system’s poor state and, in fact, initiated the reimplementation effort from bottom-up. However, the adherence to the in-house approach did not serve them well because it was too much spoiled by management.
6. Transition to COTS
This short section describes the events that happened in late 2011–early 2012, after I had left Si-Trans.
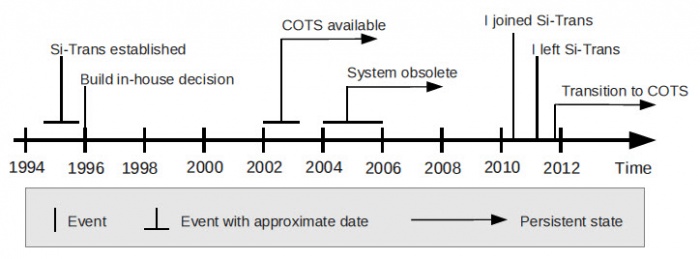
Figure 7: The timeline: 1995–2012. Embracing the COTS.
6.1 Aftermath
In November 2011, top management of Si-Trans decided to shift the software paradigm of the company to the COTS-based development. They fired the software engineering staff except for a team lead who had both deep domain knowledge and technical skill in building information systems. In December 2011, Si-Trans started joint analysis with 1C on adopting 1C:Enterprise—still by far the most widespread enterprise management system in Russia. Adaptation engineers from 1C started collaboration with the Si-Trans’ higher executives to elicit the set of 1C ready-to-deploy components to use and the set of Si-Trans-specific components to implement.
The former development team lead left Si-Trans in March 2012. According to him, he did not want to participate in “yet another turn of this idiocy”. As he was the last person I knew well enough at Si-Trans, this concludes the story of software development and procurement at Si-Trans.
6.2 Interpretation: On Right Track 6 Years Late
Top management of Si-Trans, despite their shortsightedness, were able to notice the enormous losses from developing the old information system. Stability and availability issues as well as the need to pay a team of five software developers every month were strong enough arguments to reconsider the whole paradigm of in-house software creation.
It is not clear whether top management identified the sources of problems—management style, outgrown architecture, and technical debt—or just intuitively decided to try another option because their current way of doing things did not yield enough benefit. I believe, however, that the implementation attempt was a convincing argument that, for whatever reasons, the company can barely handle the in-house development. Probably, based on this evidence top management decided to start a transition to COTS.
7 Lessons Learned
Si-Trans started developing an information system in-house back in 1996, when the business context required agility to adapt to the rapidly changing circumstances. As the information system evolved through mid-2000, its architecture grew less and less appropriate, while its codebase grew less and less manageable. At approximately the same time, an advantageous COTS alternative emerged, but it was ignored by the top management of Si-Trans. When I joined the company in 2010, the information system was at the peak of its technical debt; adding to all that, detrimental management practices incessantly pulled the development down. Shortly after I left Si-Trans, top management drastically changed the software paradigm to COTS-based development. This long-needed change arrived 6 years late, but better late than never.
I draw the following conclusions from the story of Si-Trans:
• Business logic changes and thick clients — the thick client architecture is poorly maintainable when business logic (a) gets complicated and (b) changes frequently. This is true because the business rules are lost in source code. Development can continue only if all programmers know—or at least can quickly find—all the business rules, which is not true in case of the thick client architecture. When using this architecture, the technical debt piles up faster, and the software reliability drops.
Si-Trans kept developing a thick client system for 15 years. Frequent changes in business rules eroded the code so that it would take much time to find and extract the rules from it. As the size of the system grew, it became increasingly harder to ensure integrity between the rules. As a result, occasional inconsistencies in the implementation amassed and severely damaged the reliability of the system.
• Management and debt — a volatile, chaotic, and noncommittal management style speeds up the accumulation of technical debt because development-level requirements change too often. Excessive workload pressure on programmers also makes technical debt grow faster: bugs are left behind, and new features are built as workarounds.
There were three main ways in which the chaotic and inconsistent management of Si-Trans accelerated the rate at which the technical debt was created. First, the frequently changing, sometimes contradictory requirements broke programming abstractions, which resulted in the ball of mud source code [8]. Second, permanent time pressure on software developers resulted in leaving old issues in the system and building new ones on top of the low-quality code. Third, the reluctance of the executives to strategically invest man-hours into fixing bugs made engineers build the system on workarounds. This contradicted a common software engineering wisdom that proscribes creating new code assuming that old bugs exist [16].
• Stability in management and environment — for a software project without fixed requirements, there is a “degree of volatility” in management that defines how flexible a software development process is with respect to the requirements. There should be a match between this degree of volatility and the stability of the project’s environment, which is capable of evolving and, hence, changing the requirements. Stable environments should be matched with a more fixed, rigid process, while volatile environments are better approached with a more agile development process.
Si-Trans’ software process can be characterized as very lightweight and flexible. This was appropriate in the unpredictable environment of 1996-2000. However, as the environment stabilized, the flexibility of process and the active search of new requirements did not give much advantage; conversely, it undermined deep domain analysis and disciplined code reuse.
• Continuous monitoring of the buy vs. build question — the issue of buying COTS or building software in-house should not be treated as a one-time question. Constant reevaluation of fitness for buying or building helps not miss beneficial opportunities as an environment changes. Engineers should be equipped with time and authority to collaborate with management on this question.
The sunk cost bias might have been one of reasons why Si-Trans missed a COTS acquisition opportunity. Top managers might not have considered acquisition at all because this would mean throwing away the organic system that had received huge investments: developers’ salaries over many years; efforts of the management to govern the development; time lost by the system’s users because of faults, low performance, and counterintuitive interfaces. Another reason might have been that the high executives were not aware of how suitable and extensible 1C was. The software team could not help because they lacked time budget to investigate 1C. In any case, an objective cost-benefit analysis in 2006-2011 would have revealed that adopting 1C had been a more advantageous option then sticking with the downhill in-house engineering.
• Benefiting from control dilution — if a company partly loses its control over software development as result of acquiring COTS, is often seen as a disadvantage of buying software [17]. However, the lack of control caused by COTS can prevent volatile management practices from eroding the software because COTS solutions preserve their assumptions and code. So, the lack of control over a software process may help in case of chaotic management practices.
Many issues with the in-house development at Si-Trans came, in my opinion, from the excessive control of top management over the flexible development process. Had there been a force keeping the requirements from drifting, the old information system might not have had many of its problems. A COTS-based immutable architecture might have been such a force.
© Ivan Ruchkin, Institute for Software Research Carnegie Mellon University, May 9, 2012.
References
[1] Eric Allman. Managing technical debt. Queue, 10(3):10–17, March 2012.
[2] Carina Alves and Anthony Finkelstein. Challenges in COTS decision-making: a goal-driven requirements engineering perspective. In Proceedings of the 14th international conference on Software engineering and knowledge engineering, SEKE ’02, pages 789–794, New York, NY, USA, 2002. ACM.
[3] Lisa Brownsword, Carol A. Sledge, and Tricia Oberndorf. An activity framework for COTSBased systems. Technical Report CMU/SEI-2000-TR-010, Carnegie Mellon University, Software Engineering Institute, 2010.
[4] David Carney and Fred Long. What do you mean by COTS? Finally, a useful answer. IEEE Softw., 17(2):83–86, March 2000.
[5] 1C Company. 1C:Enterprise 8 - the system of programs. http://v8.1c.ru/eng/the-system-ofprograms/.
[6] Allen Eskelin. Technology Acquisition: Buying the Future of Your Business. Addison-Wesley Professional, 1 edition, June 2001.
[7] M. D. Feblowitz and S. J. Greenspan. Scenario-Based analysis of COTS acquisition impacts. Requirements Engineering, 3(3-4):182–201, March 1998.
[8] Brian Foote and Joseph Yoder. Big ball of mud. http://www.laputan.org/mud, 2000.
[9] Patricia K. Lawlis, Kathryn E. Mark, Deborah A. Thomas, and Terry Courtheyn. A formal process for evaluating COTS software products. Computer, 34(5):58–63, May 2001.
[10] Jingyue Li, Reidar Conradi, Odd Petter, N. Slyngstad, Christian Bunse, Umair Khan, Marco Torchiano, and Maurizio Morisio. An empirical study on Off-the-Shelf component usage. In Industrial Projects. Proc. 6th International Conference on Product Focused Software Process Improvement (PROFES’2005), 13:13–16, 2005.
[11] Jingyue Li, Reidar Conradi, Odd Petter N. Slyngstad, Christian Bunse, Marco Torchiano, and Maurizio Morisio. An empirical study on decision making in off-the-shelf component-based development. In Proceedings of the 28th international conference on Software engineering, ICSE’06, pages 897–900, New York, NY, USA, 2006. ACM.
[12] B. Craig Meyers and Patricia Oberndorf. Managing Software Acquisition: Open Systems and COTS Products. Addison-Wesley Professional, 1 edition, July 2001.
[13] Abdallah Mohamed, Guenther Ruhe, and Armin Eberlein. COTS selection: Past, present, and future. In Engineering of Computer-Based Systems, 2007. ECBS ’07. 14th Annual IEEE International Conference and Workshops on the, pages 103–114. IEEE, March 2007.
[14] Maurizio Morisio and Marco Torchiano. Definition and classification of COTS: a proposal. In Proceedings of the First International Conference on COTS-Based Software Systems, ICCBSS ’02, pages 165–175, London, UK, 2002. Springer-Verlag.
[15] Vijay Sai. COTS acquisition evaluation process: The preacher’s practice. In Proceedings of the Second International Conference on COTS-Based Software Systems, ICCBSS ’03, pages 196–206, London, UK, 2003. Springer-Verlag.
[16] Joel Spolsky. Joel on Software: And on Diverse and Occasionally Related Matters That Will Prove of Interest to Software Developers, Designers, and Managers, and to Those Who, Whether by Good Fortune or Ill Luck, Work with Them in Some Capacity. Apress, August
2004.
[17] Kurt Wallnau, Scott Hissam, and Robert C. Seacord. Building Systems from Commercial Components. Addison-Wesley Professional, 1 edition, August 2001.