
1C:Enterprise 8.3. Developer Guide. Contents
JOB MECHANISM
The job mechanism is designed to run application functionalities as scheduled or asynchronously.
The job mechanism has the following tasks:
defining scheduled procedures at the stage of system configuration
performing specified actions as scheduled
calling a specified procedure or function asynchronously, i.e. without waiting for its completion
tracking progress for a job and getting its completion status (a value that indicates successful or unsuccessful completion)
obtaining a list of current jobs
waiting for completion of a single or multiple jobs
managing jobs (cancelling, locking execution, etc.)
The job mechanism includes the following components:
scheduled job metadata
scheduled jobs
background jobs
Job Scheduler
Scheduled jobs are used to perform application tasks as scheduled. These jobs are stored in the infobase and based on metadata defined in the configuration. Scheduled job metadata contain such data as description, method, use, etc.
A scheduled job has a schedule that defines when the job-related method is to be executed. As a rule, schedules are set up in the infobase, though they can also be created at the configuration stage (e.g., for predefined scheduled jobs).
Background jobs are used to perform application tasks asynchronously and are implemented through the 1C:Enterprise script.
Job Scheduler is used to plan execution of scheduled jobs. The Job Scheduler runs periodic checks for each scheduled job to see if the current date and time matches the job schedule. If it does, the Scheduler assigns this job to be executed. For this purpose the Scheduler creates a background job that is actually responsible for processing.
18.1. BACKGROUND JOBS
Background jobs are useful for complex calculations that might take a long time to obtain the result. Using the job mechanism tools these calculations can be done asynchronously.
Background jobs have an associated method invoked when a job runs. Background job method can be any procedure or function of a non-global common module that can be called at the server. Background job parameters can take any values that can be passed to the server. Background job parameters must match parameters of the called procedure or function exactly. If a function is used as a background job method, its return value is ignored.
A background job can have a key – any application value. The key applies constraints to background job startup – only one background job with a specific key value and method name (comprising module name and procedure/function name) can run at one time. The key allows the user to group background jobs with identical methods based on an application characteristic. Thus, only one background job can be executed within a certain group.
Background jobs can be created and managed programmatically within any connection. Any user can create background jobs. In this case the job is performed under the account of the user that created it. A user with administrative permissions or the user that created the jobs can get them and wait for their completion within any connection.
Background jobs are purely session objects; they do not belong to any user sessions. For each job, a special system session is created under the account of the calling user. Background jobs have no saved state.
They can generate other background jobs. This feature can be used in the client/ server mode to run concurrent cluster working processes for complex calculations, thus accelerating the overall calculation process. Concurrency is implemented through generating multiple child background jobs and waiting for their completion in the parent background job.
Background jobs can place data in temporary storages of calling sessions (see page 2-849). This functionality can be used, for example, to transfer a generated report or data to be processed to the calling session. Data transfer from a calling session to a background task session is not supported.
Successfully completed or failed background jobs are stored for 24 hours and then are deleted. If the number of completed jobs is over 1000, the oldest jobs are also deleted. This quantity relates to one base for a file-based variant of an infobase, and to one cluster for a client/server variant.
18.2. SCHEDULED JOBS
Scheduled jobs are used to perform periodic or one-time actions in compliance with a schedule.
These jobs are stored in the infobase and based on scheduled job metadata defined in the configuration. Metadata specify such scheduled job parameters as invoked method, description, key, availability for use, predefined flag, etc. When a scheduled job is created, the user can additionally specify its schedule (in the metadata), method parameter values, user name to be used to run the job, etc.
Scheduled jobs can be created and managed programmatically within any connection. They are available only to users with administrative permissions.
NOTE
In the file-mode scheduled jobs can be created and edited without launching the Job Scheduler.
Scheduled jobs have an associated method invoked when a job runs. Scheduled job method can be any procedure or function of a non-global common module that can be called at the server. Scheduled job parameters can take any values that can be passed to the server. Scheduled job parameters must match parameters of the called procedure or function exactly. If a function is used as a scheduled job method, its return value is ignored.
A scheduled job can have a key – any application value. The key applies constraints to scheduled job startup as out of all the scheduled jobs associated with the same metadata object only one job with a specific key value can run at one time. The key allows the user to group scheduled jobs associated with the same metadata object based on an application characteristic. Thus, only one scheduled job can be executed within a certain group.
Predefined scheduled jobs can be created at the configuration stage. Predefined scheduled jobs are no different from ordinary scheduled jobs, except that they cannot be explicitly created and deleted. If scheduled job metadata have the predefined flag, the predefined scheduled job is auto-generated in the infobase when the configuration is updated. If the predefined flag is unchecked, the predefined scheduled job is automatically removed from the infobase when the configuration is updated. Initial values for predefined scheduled job properties (e.g., schedule) are set in metadata. The user can modify these values when working in the application. Predefined scheduled jobs have no parameters.
Schedule for a scheduled job defines when the job is to be launched. Schedules can specify:
start and end date and time for a job;
execution period;
week days and months to run a scheduled job etc. (see the "1C:Enterprise Script Description").
Sample Schedules for Scheduled Jobs
|
Schedule |
Parameter values |
|
Every hour, only one day |
DaysRepeatPeriod = 0 RepeatPeriodInDay = 3600 |
|
Each day once a day |
DaysRepeatPeriod = 1 RepeatPeriodInDay = 0 |
|
One day, one time |
DaysRepeatPeriod = 0 |
|
Once in two days, once a day |
DaysRepeatPeriod = 2 |
|
Each day, every hour from 01.00 to 07.00 |
DaysRepeatPeriod = 1 RepeatPeriodInDay = 3600 BeginTime = 01.00 EndTime = 07.00 |
|
Each Saturday and Sunday at 09.00 |
DaysRepeatPeriod = 1 WeekDays = 6, 7 BeginTime = 09.00 |
|
Each day for a week, skip a week |
DaysRepeatPeriod = 1 WeeksPeriod = 2 |
|
At 01.00 once |
BeginTime = 01.00 |
|
Last date of each month at 09.00 |
DaysRepeatPeriod = 1 DayInMonth = -1 BeginTime = 09.00 |
|
Fifth day of each month at 09.00 |
DaysRepeatPeriod = 1 DayInMonth = 5 BeginTime = 09.00 |
|
Second Wednesday of each month at 09:00 |
DaysRepeatPeriod = 1 WeekDayInMonth = 2 WeekDays = 3 BeginTime = 09.00 |
It can be checked whether a job is executed for the specified date (ExecutionRequired() method of JobSchedule object). Scheduled jobs are always performed under a specific user account. If a scheduled job user is not specified, the job is executed with the default role rights assigned for the configuration. If the default role is not assigned for the configuration, the job is executed with no access rights restriction.
Scheduled jobs are performed using background jobs. When the Scheduler determines that a scheduled job should be performed, it creates a background job based on this scheduled job that performs the further processing. If the scheduled job is already running, it is not launched again regardless of its schedule.
Scheduled jobs can be re-launched. It is particularly important when execution of the scheduled job method needs to be guaranteed. A scheduled job needs to be re-launched if it fails or if a working process (client/server mode) or client process (file-mode version) used to execute the scheduled job fails. A scheduled job can specify the number of times that job needs to be restarted (Restart count on failure property), and an interval between restarts (Restart interval on failure). When a scheduled number of restarts has been completed, start attempts stop until the time for starting that scheduled job comes around once again (as per schedule).
A restart counter resets, and in case of failure of a scheduled job, the restart process starts again.
When implementing the re-launched scheduled job method, please bear in mind that re-launching the job executes it from the beginning rather than the point of failure.
18.3. RUNNING BACKGROUND JOBS IN FILE MODE AND CLIENT/SERVER MODE
Background job mechanisms are different for file mode and client/server mode.
18.3.1. File Mode
Background and scheduled tasks are performed by client applications or web server extensions. Background tasks are performed in the client application that initiated the launch of a background task. Background tasks are executed sequentially, i.e. only one background task can run in one client application. If a web server is used, the sequential execution of background and scheduled jobs is supported for each infobase accessed via this web server.
The behavior of background and scheduled jobs in a file-based variant is distinguished by the following:
Information on background tasks called with the help of script methods or executing reports is only available in the client application that executed the tasks. Information is not stored after a client application completes its work.
Information on background tasks initiated by scheduled jobs is available to all client applications. It is saved between launches.
Scheduled jobs are executed by one client application. You can disable launching scheduled tasks by a certain client application or enforce a certain client application to function as a scheduled job executor. This can be done through the following:
○ /AllowExecuteScheduledJobs command line parameter for thick and thin client applications.
○ allowexecutescheduledjobs attribute of element point of default.vrd publication file (see book "1C:Enterprise 8.3. Administrator Guide") if the infobase is published on a web server.
Scheduled jobs are the first ones to be executed (in the launching order) by the client application that is not prohibited from performing scheduled jobs. When a client application session is over, the execution is handed over to a client application that is still running. If a client application is launched and the requirement to execute scheduled jobs is explicitly set, scheduled jobs are executed by this client application regardless of whether there are other client applications (including web server extensions).
Scheduled jobs are executed by a web server extension until it serves at least one client session.
Scheduled jobs are processed once every 60 seconds.
18.3.2. Client/Server Mode
The client/server mode runs background jobs using the Job Scheduler that is physically located in the cluster manager. The Scheduler gets the least busy working process for all the queued background jobs and uses it to run the appropriate job. The working process executed the job and notifies the Scheduler of the results.
In the client/server mode, execution of scheduled jobs can be locked. Locks are used in the following cases:
An explicit lock of scheduled jobs is applied to the infobase. The lock can be set in the cluster console.
A connection lock is applied to the infobase. The lock can be set in the cluster console.
SetExclusiveMode() method with True parameter has been called from the 1C:Enterprise script.
In some other cases (e.g., when the database configuration is updated).
18.4. CREATION OF SCHEDULED JOB METADATA
Before a scheduled job can be programmatically created in the infobase, it has to have a metadata object created.
To create a metadata object for a scheduled job, select Add in the configuration tree Common branch for the Scheduled jobs branch.
Scheduled jobs have a set of properties described below.
Method name – name of the scheduled job method.
Key – a random string value to be used as the scheduled job key.
Schedule – scheduled of a scheduled job. To generate a schedule click Open and select the required values in the schedule form that opens.
On the General tab, specify job start and end dates and repeat mode (see fig. 310).
The Daily tab contains job schedule for a day (see fig. 311).
The following can be included in the schedule:
job start and end time
job end time that forces the job to complete
job repetition period
duration of pause between repetitions
duration of execution

Fig. 310. Common Schedule

Fig. 311. Schedule for a Day
You can combine these conditions at will.
The Weekly tab contains job schedule for a week.
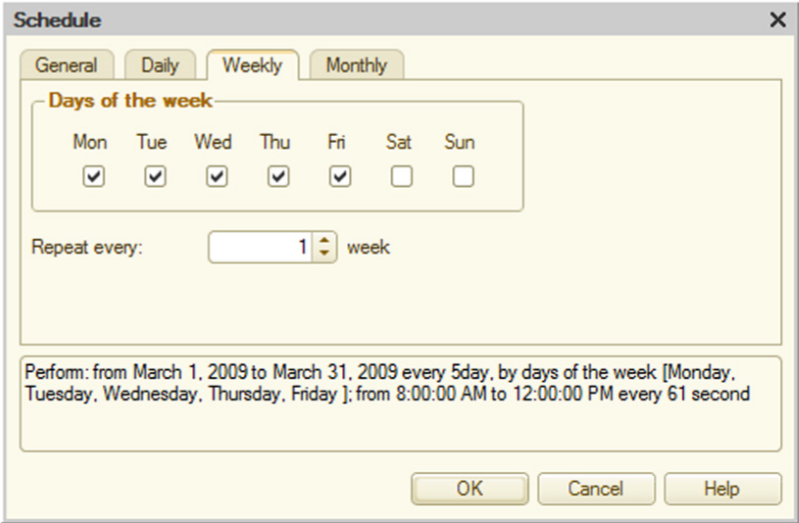
Fig. 312. Schedule for a Week
Check the days of week when the job has to be executed. If it is necessary to execute the job repeatedly, specify repetition interval in weeks. For example, if a job is executed once in two weeks, repetition value is 2.
The Monthly tab contains job schedule for a month.

Fig. 313. Schedule for a Month
Check the months when the job has to be executed. If necessary, you can define specific day of week or month for execution. You set it as a value from the beginning or end of week or month.
Use – if it is set, the job is performed according to the schedule.
Predefined – if it is set, the job is predefined.
Restart count on failure – number of attempts to restart at abortion.
Repeat interval on failure – interval between attempts to restart at abortion.
Creation of Sample Background Job "Update Full Text Search Index":
BackgroundJobs.Execute("UpdateFullTextSearchIndex");
Creation of Sample Scheduled Job "Restore Sequences":
Schedule = New JobSchedule;
Schedule.DaysRepeatPeriod = 1;
Schedule.RepeatPeriodInDay = 0;
Job = ScheduledJobs.CreateScheduledJob("RestoreSequences");
Job.Schedule = Schedule;
Job.Write();