
1C:Enterprise 8.3. Developer Guide. Contents
DATA COMPOSITION SYSTEM
The data composition system is intended for generation of 1C:Enterprise reports based upon their declarative description. Using declarative descriptions for the reports allows to do the following:
Create reports without any coding;
Create various report variants;
Specify user settings in various variants;
Use automatically generated view and settings forms for the reports;
Break down report's execution into stages;
Execute different stages of report generation on different machines;
Use components of the data composition system independently;
Modify the report's execution process programmatically;
Configure the report's structure; Combine several tables in the report; Create nested reports, etc.
Features of the data composition system are used in the following cases:
In dynamic lists (see page 1-369),
In preparing data for further processing (e.g., in data processors).
10.1. GENERAL INFORMATION ON DATA COMPOSITION
The data composition system is a set of items, each representing a report execution stage. Therefore, the entire report execution process in the data composition system is perceived as a sequence of transitions from one item to another, eventually reaching the completed report stage.
Each item of the data composition system has its own declarative description, program access and serialization to/from XML. This approach allows flexible management of different report execution stages.
The main items of the data composition system are demonstrated on fig. 225.

Fig. 225. Main Items of Data Composition System
The data composition schema describes the essence of data provided for reporting (where to receive data from and how to manage data composition). It represents a basis for report generation. It can contain:
Query text with the data composition system instructions
Description of several data sets
Description of available fields
Description of links between several data sets
Description of data receiving parameters
Description of field and group templates, etc.
The data composition settings describe everything a developer or a user can set up in the specified data composition schema. They can include:
Filter
Ordering
Conditional appearance
Report structure (parts of the future report)
Data receiving parameters
Data output parameters, etc.
The data composition template represents a predefined description as to how to create a report. It combines composition schemas and settings. It actually results from applying specific settings to the composition schema and represents a finished task for the composition processor to generate a report with the required structure and specified settings.
The data composition result item is a set of items of the data composition result. The data composition result does not exist as an independent logical entity, only its items do. Items of the data composition result can be output to a spreadsheet document for presentation to the end user or to other types of documents. The data composition process consists of several stages, as shown on fig. 226.

Fig. 226. Stages of Data Composition Process
The data composition schema can be created in the following ways:
Visually, using the data composition schema wizard
Visually, using any editor that allows editing XML text
Using a program with 1C:Enterprise script objects
Editing the data composition settings can use a number of dedicated
1C:Enterprise script objects and table box extensions.
Preparing to execute is a process of generating a data composition template. This process generates queries required to obtain the data specified in the settings and it also creates report area templates.
Data composition execution is a process of obtaining, aggregating and formatting the data.
Output of data composition result: the obtained composition result can be output to a document to be shown to the user. A report can be output in various formats.
The schema on fig. 227 below demonstrates the data composition system objects used at different report generation stages in generalized view.
The data composition schema wizard can be used for creating the data composition schema.
The data composition settings composer can be used for editing settings of the data composition system.

Fig. 227. Data Composition System Objects
The data composition template composer is used at the execution preparation stage.
The data composition processor executes data composition.
Processor of outputting the data composition result to a spreadsheet document outputs items of the data composition result to a spreadsheet document.
Reports obtained using the data composition system are distinguished by a complex structure that includes various combinations of the following items:
Groups
Tables
Plans
Nested reports
Thus, a report obtained using the data composition system is not simply a table, but a complex hierarchical structure of the listed items (see fig. 228).
This figure shows a sample report containing a chart and product groups at the first hierarchical level. A particular product group contains a table with turnovers for a product belonging to the group.

Fig. 228. Report Structure
10.2. COMMON OBJECTS OF DATA COMPOSITION SYSTEM
10.2.1. Use Property
Multiple objects, in particular subsystems of data composition settings, own a Boolean-type Use property. This property is used to partially disable functionalities without physical removal. This property is set to True by default, although there are some exceptions.
10.2.2. Data Composition System Field
This object represents a path to field data. The field is implemented as a separate type that disambiguates properties of some objects that can take on both string and field values. It has a constructor with the String parameter, which stores a path to data, and does not have properties or methods. If the path to data contains identifiers with spaces or special characters, these identifiers must be enclosed in brackets.
10.2.3. Data Composition System Parameters
Parameters have been implemented to ensure consistent use and change of value collections where value lists and item types are predefined and cannot be changed. This mechanism includes two parts:
Available parameters that define the collection content and valid item types. A parameter is similar to a data composition system field.
Parameter values.
10.3. DATA COMPOSITION SCHEMA
The data composition schema is represented by the 1C:Enterprise script DataCompositionSchema object and consists of multiple nested objects. The data composition schema is presented as XML so that it can be created by any tools that allow generating XML and used by any tools that can read XML.
The data composition schema is used to provide information on available settings, format the data composition template (see page 1-617), i.e. to execute data composition.
The data composition schema wizard is used for visual editing of the data composition schema (see page 1-589).
Data composition schema can be loaded from XML using the standard
1C:Enterprise script tools.
XMLReader = New XMLReader;
XMLReader.SetString(
FormElements.DataCompositionSchemaText.
GetText());
DCS = XDTOSerializer.ReadXML(
XMLReader,
Type("DataCompositionSchema"));All expressions, described in the data composition schema, are written in the data composition system expression language (see page 1-547).
10.3.1. Data Composition Schema Components
Each data composition schema contains a variety of objects that describe its components. Let us review these sections:

Fig. 229. Data Composition Schema Components
10.3.1.1. Data Sources
A data composition schema may contain several data sources.
A data source means a source from where data are retrieved. 1C:Enterprise infobase is used as a data source.
Data sources are described in the schema's DataSources property that contains a value collection consisting of DataCompositionSchemaDataSource items.
10.3.1.2. Data Sets
Data sets in data composition schemas contain information on what fields can be retrieved from this set, what data set fields can be used for filtering, etc.
The data composition schema allows the presence of several data sets (see page 1-542).
Data sets are described in the schema's DataSets property. This property contains a value collection that can include the following items:
Query (DataCompositionSchemaDataSetQuery) – data retrieval is described using the query language;
Object (DataCompositionSchemaDataSetObject) – describes the name of an external data set to be used to retrieve data;
Union (DataCompositionSchemaDataSetUnion) – describes the data sets included in the union.
All the three data sets have common properties:
Name – the data set name to be used to address this data set from other objects of the data composition schema. Within a single data composition schema data set names must be unique;
Fields – a description of the fields available for the data set.
Additionally data sets (queries and objects) contain the DataSource property that represents the name of a data source from where data are retrieved. It must contain the name of a data source from the data composition schema (see page 1-537).
Query data sets contain the Query property, i.e. the query text to be used to retrieve data from the data source. The query text is written in data source terms. Thus, for a Local data source type, the query text will be written in 1C:Enterprise query language terms using a special extension – a query language extension for the data composition system (see page 1-544).
A union data set contains the Items property that lists the data sets included in the union (see page 1-538). Query Data Set
It contains a standard query to the data in the 1C:Enterprise infobase.
A query data set can contain a batch query. The resulting query is a batch query. The set of fields to be placed in a temporary table is automatically defined based on the fields used in other queries. If no temporary table fields are required, the temporary table is not added to the resulting query. The filter used in the data composition settings is applied to all queries of the batch.
The data set content is the result of the last query in the batch.
Only one data source can be accessed within a single dataset (including external data sources).
Object Data Set
An object data set is used to output information from a 1C:Enterprise object in a report; the object can be a value table, a query result, a current document, etc.
This data source is described in the data composition schema, filled programmatically, e.g., using a button and passed to the data composition processor as an external data source. Union Data Set
A union data set contains the Items property that describes the data sets to be merged.
Please note that field values of a union data set are retrieved from the fields of nested data sets using their data paths. Thus, in the above example, the external data set includes the ExpAmount field; and the field data are retrieved from the nested data sets with the ExpenseAmount data path. Data Composition Schema Data Set Field
A data set can contain descriptions of fields available for this data set.
The data set fields are described in the DataSetFields property that contains a value collection consisting of DataCompositionSchemaDataSetField items.
10.3.1.3. Data Set Links
The data sets included in the data composition schema can be linked to each other.
The data set links are described in the DataSetLinks property of the data composition schema; this property contains a value collection consisting of the DataCompositionSchemaDataSetLink items.
10.3.1.4. Calculated Fields
The data composition schema has a capability to describe fields that will be calculated by certain expressions using data set fields. These fields can be used in settings similarly to data set fields.
Calculated fields are described in the DataCompositionSchemaCalcula- tedFields property of the data composition schema; this property contains a value collection consisting of DataCompositionSchemaCalculatedField items.
10.3.1.5. Resource Fields
The data composition schema can contain a description of resource fields whose values are to be calculated for group records. This is done using total field description.
Total fields are described in the TotalFields property of the data composition schema; this property contains a value collection consisting of DataComposi- tionSchemaTotalField items. Every record from the data set for which the resource gets calculated, is used in this calculation only once.
10.3.1.6. Parameters
The data composition schema contains a description of the data parameters.
The data parameters are described in the data composition schema parameters property that contains a value collection consisting of DataCompositionSche- maParameter items.
You can specify the parameter mandatory attribute and make the parameter obligatory to fill. For example, using a combination of these attributes you can implement a parameter which, if it is not entered, prevents generation of a report.
10.3.1.7. Nested Schemas
The data composition schema can contain descriptions of nested data composition schemas.
Nested data composition schemas are described in the NestedDataCompositionSchemas property of the data composition schema; this property contains a value collection consisting of NestedDataCompositionSchema items.
10.3.1.8. Templates
Templates to be used for outputting a field or a group can be described in the data composition schema. When specifying a template for a field or a group, indicate the name of the template described in this property.
Templates are described in the data composition schema templates property. This property contains a value collection consisting of DataCompositionSchemaTemplateDescription items.
10.3.1.9. Field Templates
Each data composition schema field can be assigned a name of a template used to output the field in the composition result.

Fig. 230. Field Templates
A link between a field and a template is described using the DataComposi- tionSchemaFieldTemplate object. A collection of these objects is included in the FieldTemplates property of the DataCompositionSchema object.
10.3.1.10. Group Templates
Each data composition schema group can be assigned a name of a template used to output the group in the composition result.
A link between a group and a template is described using the DataCompositionSchemaGroupTemplate object. A collection of these objects is included in the GroupTemplates property of the DataCompositionSchema object.
10.3.1.11. Group Header Templates
Group header templates can also be described for each group.
A link between a group header and a template is described using the DataCompositionSchemaGroupTemplate object (see the previous section). A collection of these objects is included in the GroupHeaderTemplates property of DataCompositionSchema object.
10.3.1.12. Default Settings
Each report variant set up in the data composition schema contains the default data composition settings that can be specified by the developer. The variant listed first in the variant list for the data composition system settings is assigned as default (the Chart by periods variant on fig. 231). The default variant settings are applied when the report is first opened, the More – Set standard settings (All actions – Set standard settings) command is selected or the default settings need to be programmatically set up.

Fig. 231. Default Variant
For details on data composition settings see page 1-599.
10.3.2. Working with Multiple Data Sets
The data composition system allows using several data sets in a single composition.
In order to use multiple data sets in a single composition, add the data set descriptions to be used to the schema and specify links between the data sets.
Review the following example.
Write three data sets: PriceList, Balance and Sales.

Fig. 232. Example with Multiple Data Sets
Define links between the data sets. Create a link between PriceList and Balance data sets and another link between PriceList and Sales data sets (see fig. 233).

Fig. 233. Data Set Links
Add resource descriptions (see fig. 234).

Fig. 234. Data Composition Schema Resources
If the data composition system describes a link between two data sets, the destination data set is considered dependent. The source data set is considered a parent in relation to the dependent data set.
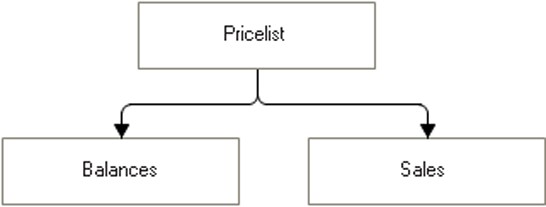
Fig. 235. Dependent Data Sets
In the examples above, the Balance and Sales data sets are dependent. The PriceList data set, on the other hand, is their parent.
There is no indication about the link type in the data composition schema. All links are considered left external joins. I.e., a parent data set record is used in the composition even if there are no records in the dependent set.
You can indicate the link type in the data composition template (see page 1-617). The link type is generated by the template composer depending on the applied global filters. If a global filter is applied to a dependent data set field, links between this data set and its parents generated in the data composition template (up to the top of the data set hierarchy) are Inner. It means that parent data set records are included in the composition only if records are found in the dependent data sets.
For example, if the user applies a global filter to the Warehouse field, the PriceList and Balance data sets are bound by an inner link.

Fig. 236. Inner Link
If a data set is dependent on a certain data set and the link allows using a parameter list, data from the dependent data set are obtained in portions of 1000 records. If using the parameter list is not allowed in the link, records are obtained one by one.
If dependent and parent data sets contain a field with the same name, this field is obtained from the parent data set. In the examples provided, the Nomenclature field is always obtained from the PriceList data set.

Fig. 237. Common Field
The unlinked data sets cannot contain fields with the same name if they do not have the same parent with the given field. Thus, the Balance and Turnovers data sets can contain the Nomenclature field, but they cannot both contain the Contractor fields.
In the link description, fields from the source data set (the parent set) are used in the source expression; fields from the destination data set (the dependent data set) are used in the destination link expression. Thus, to describe a link between the PriceList and Balance data sets, the Nomenclature expression in the SourceExpression property uses the PriceList data set field, while the Nomenclature expression in the DestinationExpression property uses Balance data set field.
Fields from unlinked data sets cannot be used in a single group and data sets with the same parent are not considered linked. The only exception is total fields that can be used in any group. In the example above, you cannot use the Warehouse and Contractor fields in the same group. However, you can use CountBalance and SumTurnover, because they are resource fields.
The data from a dependent data set cannot be obtained without obtaining the parent set data. It means obtaining data from a dependent set automatically retrieves data from the parent set (and all of its parents). In the above example, when you obtain the Balance data set, data from the PriceList set is also retrieved.
If a group uses data sets from multiple data sets, iteration is performed in the last dependent data set during composition. Thus, if a group uses fields of the PriceList and Balance sets, iteration is performed in the Balance set.
If no field from the linked data set is used in the settings, the data set is not included in the data composition template.
10.3.3. Query Language Extension for Data Composition System
A query language extension for the data composition system is performed using special syntax instructions enclosed in braces and placed directly in the query text.
10.3.3.1. Syntax Elements of Query Language Extension for Data Composition System
SELECT
Description:
This clause describes the fields that can be selected by the user for output. This keyword is followed by comma-separated field aliases from the main query selection list that are available for setup.
A field alias can be followed by a combination of ".*" characters that imply child fields of this field can be used.
Thus, Nomenclature.* means Nomenclature child fields (e.g., Nomenclature.Code) can be used. The SELECT element can only be included in the first query of a union.
Example:
{SELECT Nomenclature, Warehouse}
WHERE
Description:
It describes the fields where the user can apply filtering. This clause uses table fields. Selection list field aliases are not allowed. Each union part can contain its own WHERE element.
If no parameter values are specified, the WHERE clause is no included in the resulting query.
Example:
{WHERE Nomenclature.*, Warehouse }
{WHERE Document.Date >= &BeginDate, Document.Date <= &EndDate}CHARACTERISTICS
Description:
In order to support work with characteristics in the query language extension for the data composition system, characteristics description syntax has been introduced.
The above example describes the characteristics of Ref fields in the Nomenclature catalog.
Characteristics describe the following properties:
TYPE – the name of the type for which characteristics are described;
CHARACTERISTICTYPES – a name of the table or a query to obtain a list of characteristics. ALLOWED keyword is allowed in the query. In this case, a list of characteristics will only contain the characteristics that are available to the user, in line with the applicable data access limitations.
If a list of characteristics is specified by a table name instead of a query, the ALLOWED keyword is also used in the system generated query to obtain a list of characteristics.
ID – the name of the field that contains the characteristic ID;
NAME – the name of the field that contains the characteristic name;
VALUETYPE – the name of the field that contains the characteristic value type. If no value type is specified, the characteristic is assigned the Boolean type;
VALUES – a table name or a query to obtain values of characteristics;
OBJECT – the name of the field that contains the object ID (e.g., a product reference);
CHARACTERISTIC – the name of the field that contains the characteristic ID;
VALUE – the name of the field that contains the characteristic value; If it is not specified, the value is True (if an object has this characteristic); otherwise the value is False.
Example:
{CHARACTERISTICS TYPE(Catalog.Nomenclature)
LIST (SELECT
OptionTypes.Ref,
OptionTypes.Description,
OptionTypes.ValueType
FROM
ChartOfCharacteristicTypes.OptionTypes AS OptionTypes)
ID Ref
NAME Description
VALUETYPE ValueType
VALUES InformationRegister.Options
OBJECT Nomenclature
CHARACTERISTIC PropertyType
VALUE Property
}Parameters
Description:
Besides the main elements, the data composition system can receive elements written in virtual table parameters. In this case the field type depends on the type of the parameter that contains the elements.
BeginDate, EndDate, Nomenclature and Warehouse fields (see the example below) become available for filtering, i.e. the user can apply filters to them.
Example:
SELECT
NomenclatureAccountingTurnovers.Nomenclature AS Nomenclature,
NomenclatureAccountingTurnovers.Warehouse AS Warehouse,
NomenclatureAccountingTurnovers.QuantityReceipt AS QuantityReceipt,
NomenclatureAccountingTurnovers.QuantityExpense AS QuantityExpense,
FROM
AccumulationRegister.NomenclatureAccounting.Turnovers({&BeginDate},
{&EndDate},
,
{Nomenclature.*,
Warehouse.*}) AS NomenclatureAccountingTurnovers10.3.3.2. Auto Fill of Available Fields
The following is performed when available query fields are auto-filled:
All selection list fields and their child fields become available for filtering ordering, grouping, selecting, etc.
Virtual table parameters become available for filtering.
10.3.4. Data composition system expression language
The data composition system expression language is intended to create expressions used throughout the system.
Expressions are used in the following subsystems:
Data composition schema – to describe calculated fields, total fields, link expressions, etc.
Data composition settings – to describe custom field expressions.
Data composition template – to describe data set link expressions, template parameter descriptions, etc.
NOTE
Data composition expression language does not support getting a field from the expression using dot operator.
10.3.4.1. Literal constants
An expression may contain literals of the following types.
Line
Description:
A string literal is enclosed in double quotation marks (").
If you need to use double quotation marks (""") within a string literal, use two double quotation marks.
Example:
"Literal""in quotation marks"""
Number
Description:
A number is written without spaces, in decimal format. Its fractional part is separated by a period (".").
Example:
10.5 200
Date
Description:
A date literal is written using the DATETIME keyword. This keyword is followed by a year, month, day, hours, minutes, and seconds separated by commas. It is not necessary to specify the time.
Example:
January sixth, 1975 DATETIME(1975, 1, 06) // The second of December, 2006, 23 hours, 56 minutes, 57 seconds DATETIME(2006, 12, 2, 23, 56, 57)
Boolean
Description:
Boolean values may be written with True and False literals.
Value
Description:
To specify literals of other types (system enumerations, preset data), use the Value keyword followed by the literal name in brackets.
Example:
VALUE(AccountType.Active)
Fields
Description:
Expressions may contain dataset fields. A field is identified by a data path. Parts of a data path are separated by ".". Field names are not case sensitive. If a data path contains an identifier with spaces or special characters, such identifiers should be enclosed in brackets.
Example:
Nomenclature.Articul Sales.AmountTurnover Sales.[Amount turnover]
Parameters
Description:
Expressions may use parameters. To use a parameter in an expression, write its name preceded by &.
Example:
&Contractor &StartDate
Type
Description:
Creates a value of type Type. A type is set with the help of the Type keyword.
Example:
Type("String")
10.3.4.2. Operations with numbers
Unary "-"
Description:
This operation changes the sign of a number to its opposite.
Example:
-Sales.Count
Unary "+"
Description:
This operation does not perform any actions with the number.
Example:
+Sales.Count
Binary "-"
Description:
This operation calculates the difference between two numbers.
Example:
BalanceAndTurnovers.OpeningBalance - BalanceAndTurnovers.ClosingBalance BalanceAndTurnovers.OpeningBalance - 100 400 - 357
Binary "+"
Description:
This operation calculates a total of two numbers.
Example:
BalanceAndTurnovers.OpeningBalance + BalanceAndTurnovers.Turnover BalanceAndTurnovers.OpeningBalance + 100 400 + 357
Multiplication "*"
Description:
This operation multiplies two numbers.
Example:
Nomenclature.Price * 1.2 2 * 3.14
Division "/"
Description:
This operation divides one operand by another.
Example:
Nomenclature.Price / 1.2 2 / 3.14
Remainder from division "%"
Description:
This operation retrieves a remainder from dividing one operand by another.
Example:
Nomenclature.Price % 1.2 2 % 3.14
10.3.4.3. String operations
Concatenation (Binary "+")
Description:
This operation is intended for concatenation of two rows.
Example:
Nomenclature.Articul + ": " + Nomenclature.Description
LIKE
Description:
This operation checks if a string matches the transferred template.
The value of the LIKE operator is True if the Expressions value matches the template or False otherwise.
The following characters in a template line have a meaning that is different from their meaning in a simple sequence of characters:
"%" (per cent): a sequence containing zero and more random characters.
"_" (underscore): one random character;
"[…]" (one or multiple characters in square brackets): one character of those in the square brackets. Ranges can be listed as well, such as a-z. This means a random character within the range, both ends of the range included;
"[^…]" (square brackets containing a negation character followed by one or multiple characters): any character but those that follow the negation character;
Any other character represents itself only and does not have any additional use. If you need to use one of the above characters as a simple character, it should be preceded by ESCAPE.
For instance, the template below means a substring that consists of a sequence of characters: letter A
letter B
letter C
one number
one of the letters: a, b, c or d
an underscore
letter a
letter b
letter c
The sequence may start anywhere within a string.
Example:
"%ABC[0-9][abcd]\_abc%" ESCAPE "\"
10.3.4.4. Comparison operations
Equal (=)
Description:
This operation is intended to compare two operands for equality.
Example:
Sales.Contractor = Sales.NomenclatureMainSupplier
Not Equal (<>)
Description:
This operation is intended to compare two operands for inequality.
Example:
Sales.Contractor <> Sales.NomenclatureMainSupplier
Less (<)
Description:
This operation is intended to check that the first operand is less than the second one.
Example:
CurrentSales.Total < PreviousSales.Total
Greater (>)
Description:
This operation is intended to check that the first operand is greater than the second one.
Example:
CurrentSales.Total > PreviousSales.Total
Less or Equal (<=)
Description:
This operation is intended to check that the first operand is less than or equal to the second one.
Example:
CurrentSales.Total <= PreviousSales.Total
Greater or Equal (>=)
Description:
This operation is intended to check that the first operand is greater than or equal to the second one.
Example:
CurrentSales.Total >= PreviousSales.Total
Operation (IN)
Description:
This operation is intended to check the presence of a value in the list of passed values. The operation returns True if the value is found or False otherwise.
Example:
Nomenclature IN (&Product1, &Product2)
Operation to check value presence in data set (IN)
Description:
This operation is intended to check value presence in the specified data set. The data set for checking must contain one field.
Example:
Sales.Contractor IN Contractors
Operation to check NULL value (IS NULL)
Description:
This operation returns True, if it is NULL.
Example:
Sales.Contractor IS NULL
Operation to check non-NULL value (IS NOT NULL)
Description:
This operation returns True, if it is not NULL.
Example:
Sales.Contractor IS NOT NULL
10.3.4.5. Boolean operations
Boolean operations use Boolean expressions as their operands.
NOT operation
Description:
NOT operation returns True, if its operand is equal to False, and it returns False, if its operand is equal to True.
Example:
NOT Document.Consignee = Document.Shipper
AND operation
Description:
AND operation returns True, if both operands are TRUE, and False, if one of the operands is False, for instance:
Example:
Document.Consignee = Document.Shipper AND Document.Consignee = &Contractor
OR operation
Description:
OR operation returns True, if one of the operands is True, and False, if both operands are False.
Example:
Document.Consignee = Document.Shipper OR Document.Consignee = &Contractor
10.3.4.6. Aggregate functions
Aggregate functions perform certain actions on a set of data.
SUM
Syntax:
Total (Expression) Description:
The Total aggregate function calculates a total of expression values passed as an argument for all detailed records. You can pass Array as a parameter.
In this case the function will be applied to the array content.
Example:
TOTAL(Sales.SumTurnover)
COUNT
Syntax:
Count(Expression) Description:
The Count function calculates the number of non-NULL values. You can pass Array as a parameter. In this case the function will be applied to the array content.
Example:
COUNT(Sales.Contractor)
COUNT (DISTINCT)
Syntax:
Count(Distinct expression) Description:
This function calculates the number of different values. To obtain different values, specify Distinct before the Count method parameter. You can pass Array as a parameter. In this case the function will be applied to the array content.
Example:
COUNT(Distinct Sales.Contractor)
MAX
Syntax:
Max(Expression) Description:
This function obtains the maximum value. You can pass Array as a parameter.
In this case the function will be applied to the array content.
Example:
MAXIMUM(Balance.Count)
MIN
Syntax:
Minimum(Expression) Description:
This function gets the minimum value. You can pass Array as a parameter.
In this case the function will be applied to the array content.
Example:
MINIMUM(Balance.Count)
AVG
Syntax:
Avg(Expression) Description:
This function gets the mean value for non-NULL values. You can pass Array as a parameter. In this case the function will be applied to the array content.
Example:
AVERAGE(Balance.Count)
ARRAY
Syntax:
Array([Distinct] Expression) Description:
This function creates an array that includes an expression value for each detailed record.
You can use a value table as a parameter. Note that in this case the function results in an array containing the values of the first column of the value table passed as a parameter.
If an expression includes the Array function, this expression is considered to be an aggregate expression.
If the Distinct keyword is specified, the retrieved array will not include duplicate values.
Example:
ReportFunctions.StandardDeviation(Array(Sum))
VALUETABLE
Syntax:
ValueTable([Distinct] Expression1 [AS ColumnName1][, Expression2 [AS ColumnName2]], ...])
Description:
The function generates a table of values with the number of columns equal to the number of function parameters. Detailed records are retrieved from data sets that are required to compute all the expressions specified as function parameters.
If residual fields are used as function parameters, the resulting value table will include values for the entries by unique sets of measurements from other periods. Note that values are only obtained for residual fields, measurements, accounts, period fields and their attributes. The values of other fields in the entries from other periods are considered NULL.
If an expression includes the ValueTable function, this expression is considered to be an aggregate expression.
If the Distinct keyword is specified, the retrieved value table will not include rows with duplicate data.
Use the AS keyword that follows an expression used in order to create a column value to specify a name for each column.
Example:
ReportFunctions.ValueTableToString(ValueTable(Inventory AS Inventory, QuantityBalance AS Balance))
GROUPBY
Syntax:
GroupBy(<Expression>, <ColumnNumbers>) Description:
This function removes duplicates from an array.
Parameters:
<Expression>
Type: Array or ValueTable. Duplicates are deleted for the value located in this formal parameter.
<ColumnNumbers>
String type. Is used if the Expression parameter is of the ValueTable type. Numbers or names (comma-separated) of the value table columns where duplicates should be searched for. By default, this includes all columns.
Example:
GroupBy(ValueTable(PhoneNumber, Address) ,"PhoneNumber").
GETPART
Syntax:
GetPart(<Expression>, <ColumnNumbers>) Description:
The function obtains a value table that contains specific columns from the original value table.
Parameters:
<Expression>
Type: ValueTable. The table of values that the columns should be retrieved from.
<ColumnNumbers>
String type. Numbers or names (comma-separated) of the value table columns that should be retrieved.
Returned value:
A table of values that contains only the columns specified in ColumnNumbers parameter.
Example:
GetPart(GroupBy(ValueTable(PhoneNumber, Address) ,"PhoneNumber"),"PhoneNumber").
ORDER
Syntax:
GroupBy(<Expression>, <ColumnNumbers>) Description:
Intended to order the items of an array and value table.
Parameters:
<Expression>
Type: Array or ValueTable. An object to be ordered.
<ColumnNumbers>
Is used if the Expression parameter is of the ValueTable type. Numbers or names (comma-separated) of the value table columns that should be ordered. By default, this includes all columns.
Order direction or an automatic ordering attribute may be placed after each column.
Returned value:
An array or a table of values ordered in accordance with the transferred parameters.
Example:
Order(ValueTable(PhoneNumber, Address, CallDate),"CallDate Desc").
JOINSTRINGS
Syntax:
JoinStrings(<Values>, <ItemSeparator>, <ColumnSeparator>) Description:
Intended to join multiple strings into a single string.
Parameters:
<Values>
Values, the string presentations of which should be joined into a single string. If it is an Array, array items will be joined into a string. If it is a ValueTable, all the table columns and rows will be joined into a string.
<ItemSeparator>
String type. Contains a text to be used as a separator between array items and the rows of a value table. By default, it is a line feed character.
<ColumnSeparator>
String type. Contains a text to be used as a separator between the columns of a value table. By default it is ";".
Returned value:
Joined string.
Example:
JoinStrings(ValueTable(PhoneNumber, Address)).
GROUPPROCESSING
Syntax:
GroupProcessing(<Expressions>, <HierarchyExpressions>, <GroupName>) Description:
A table of values is created that contains the parameter values (in columns) for each group entry (in rows). If hierarchical grouping is used, each hierarchy level is processed separately. The values of hierarchical records are also included in a data table. In a returned object, this table of values will be located in the Data property.
The CurrentItem property will hold the row (of the value table being transferred) for which the function is currently calculated.
When implementing a function that can take group processing data as parameter, please note that NULL value can be transferred to the function as a value. This may happen, for instance, if the GroupProcessing() function is calculated and the name of the group that is currently unavailable is specified.
Parameters:
<Expressions>
The string listing the comma-separated expressions to be calculated. Each expression may be followed by the optional AS keyword and a column name of the resulting value table. Each expression describes a column of the value table being created.
<HierarchyExpressions>
The expressions to be calculated for hierarchical records. This is similar to the Expressions parameter with the only difference being that Expressions parameter is used for non-hierarchical records, and HierarchyExpressions is used for hierarchical records. If the parameter is omitted, the expressions specified in the Expression parameter are used to calculate the values for hierarchical records.
<GroupName>
Name of the group to calculate processing grouping in. If this is omitted, calculations are carried out in the current grouping. If a calculation is performed on a table and the parameter includes a null string or is blank, the value is calculated for the row grouping. When the data composition template is generated, the template composer replaces this name with the grouping name in the resulting template. If the grouping is not available, the function will be replaced with NULL.
Returned value:
DataCompositionGroupProcessingData object.
Example:
An example of how the ABCClassification() function can be implemented. This function returns 1 if the value reaches 75% of the total amount; 2, if it reaches between 75% and 95%; and 3 in other cases.
// Calculate ABC classification.
Function ABCClassification(Data) Export
Var ValueTable;
If Data = Null Then
Null is returned;
EndIf;
If ValType (Data) <> Type ("DataCompositionGroupProcessingData") Then
Message(ValType(Data));
ThrowException "Only an object of type DataCompositionGroupProcessingData can be transferred
to function ABCClassification()";
EndIf;
If not data.ProcessingTempData.Property("ABCClassificationValueTable", ValueTable) Then
// calculate the classification once during the first call
// and then remember the calculation made and use this
// calculation afterwards
ValueTable = Data.Data.Copy();
ValueTable.Columns.Add("Number", New TypeDescription("Number"));
Number = 0;
CommonAmount = 0;
For Each ValueTableString From ValueTable Cycle
ValueTableString.Number = Number;
Number = Number + 1;
If ValueTableString[0] <> NULL Then
CommonAmount = CommonAmount + ValueTableString[0];
EndIf;
EndLoop;
ValueTable.Sort(ValueTable.Columns[0].Name + " Desc");
ValueTable.Indexes.Add("Number");
CumulativeAmount = 0;
IndexOfClassA = Undefined;
IndexOfClassB = Undefined;
For Each ValueTableString From ValueTable Cycle
If ValueTableString[0] <> NULL Then
CumulativeAmount = CumulativeAmount + ValueTableString[0];
EndIf;
If CommonAmount = 0 Then
Percent = 1;|
Else |
|
|
|
Percent = CumulativeAmount / CommonAmount |
|
|
|
EndIf; |
|
|
|
If percent > 0.75 Then |
|
If IndexOfClassA = Undefined Then |
|
IndexOfClassA = ValueTable.Index(ValueTableString); |
|
ElseIf Percent > 0.90 Then |
|
If IndexOfClassB = Undefined Then |
|
IndexOfClass = ValueTable.Index(ValueTableString); |
|
EndIf; |
|
Abort; |
|
EndIf; |
|
EndIf; |
|
EndLoop; |
|
|
|
Data.ProcessingTempData.Insert("ABCClassificationValueTable", ValueTable); |
|
Data.ProcessingTempData.Insert("ABCClassificationIndexOfClassA", IndexOfClassA); |
|
Data.ProcessingTempData.Insert("ABCClassificationIndexOfClassB", IndexOfClassB); |
|
EndIf; |
|
|
|
If Data.CurrentItem = Undefined Then |
|
|
|
// GroupTotal. |
|
Null is returned; |
|
|
|
Else |
|
|
|
String = ValueTable.Find(Data.Data.Index(Data.CurrentItem), "Number"); |
|
|
|
If String = Undefined Then |
|
|
|
Null is returned; |
|
|
|
Else |
|
|
|
Index = ValueTable.Index(String); |
|
|
|
If Index <= Data.ProcessingTempData.ABCClassificationIndexOfClassA Then |
|
|
|
1 is returned; |
|
|
|
ElseIf Index <= Data.ProcessingTempData.ABCClassificationIndexOfClassB Then |
|
|
|
2 is returned; |
|
|
|
Else |
|
|
|
3 is returned; |
|
|
|
EndIf; |
|
|
|
EndIf; |
|
|
|
EndIf; |
|
|
|
|
|
EndFunction |
The following expression can be used in a composition expression to obtain a class (in a resource or a user field, for instance):
ABCClassification(GroupProcessing("Sum(SumTurnover)"))
EVERY
Syntax:
Every(<X>) Description:
The Every aggregate function determines whether a set transferred contains at least one False value.
Returned value:
True – if the set transferred contains no False value.
False – if the set transferred contains at least one False value.
ANY
Syntax:
Any(<X>) Description:
The Any aggregate function determines whether a set transferred contains at least one True value.
Returned value:
True – if the set transferred contains at least one True value.
False – if the set transferred contains no True value.
STDDEV_POP
Syntax:
STDDEV_POP(<X>) Description:
Calculates a standard deviation of the general aggregate of the set transferred.
Calculation is based on the following formula: SQRT(VAR_POP(X)).
Returned value:
Result.
STDDEV_SAMP
Syntax:
STDDEV_SAMP(<X>)
Description:
Calculates a standard deviation of a selection of the set transferred.
The calculation is based on the following formula: SQRT(VAR_SAMP(X)).
Returned value:
Result.
VAR_SAMP
Syntax:
VAR_SAMP(<X>)
Description:
Calculates the selected dispersion for the set transferred.
Calculation is based on the following formula: (SUM(X^2)-SUM(X)^2/ COUNT(X))/(COUNT(X)-1). If the number of entries in a set is equal to 1 (COUNT(X)=1), the returned value is NULL.
Returned value:
Result.
VAR_POP
Syntax:
VAR_POP(<X>)
Description:
Calculates a general aggregate dispersion for the set transferred. NULL values are ignored.
The calculation is based on the following formula: (SUM(X^2)-SUM(X)^2/ COUNT(X))/(COUNT(X)).
Returned value:
Result.
COVAR_POP
Syntax:
COVAR_POP(<Y>, <X>)
Description:
Calculates the covariation of aggregated multiple pairs of the sets transferred.
The calculation is based on the following formula: (SUM(Y*X)-SUM(X)*SUM(Y)/N)/N. N is the number of X and Y value pairs from the sets transferred, where neither X nor Y is equal to NULL. Pairs that have at least one NULL value are ignored.
Returned value: Result.
COVAR_SAMP
Syntax:
COVAR_SAMP(<Y>, <X>) Description:
Calculates a sample covariation of multiple pairs of the sets transferred.
The calculation is based on the following formula: (SUM(Y*X)-SUM(Y)*SUM(X)/N)/(N-1). N is the number of X and Y value pairs from the sets transferred, where neither X nor Y is equal to NULL. Pairs that have at least one NULL value are ignored.
Returned value:
The result of calculation or NULL if the function is applied to empty sets.
CORRELATION
Syntax:
Correlation(<Y>, <X>)
Description:
Calculates the covariation coefficient of multiple pairs of the sets transferred.
Calculation is based on the following formula: COVAR_POP(Y,X)/(STDDEV_
POP(Y)*STDDEV_POP(X)). Pairs that have at least one NULL value are ignored.
Returned value:
The result of calculation or NULL if the function is applied to empty sets.
REGR_SLOPE
Syntax:
RegressionSlope(<Y>, <X>)
Description:
Calculates the line slope.
Calculation is based on the following formula: Covar_Pop(Y,X)/Var_Pop(X).
Pairs that have at least one NULL value are ignored.
Returned value:
Result.
REGR_INTERCEPT
Syntax:
REGR_INTERCEPT(<Y>, <X>) Description:
Calculates the Y intercept of the regression line.
Calculation is based on the following formula: Average(Y)- Regr_Slope (Y, X) * Average(X). Pairs that have at least one NULL value are ignored.
Returned value: Result.
REGR_COUNT
Syntax:
REGR_COUNT(<Y>, <X>) Description:
Calculates the number of pairs without NULL.
Returned value: Result. 9
REGR_R2
Syntax:
REGR_R2(<Y>, <X>) Description:
Calculates a determination coefficient for the regression. The function is calculated without taking into account value pairs that contain NULL value.
Returned value:
NULL, if Var_Pop(X) is equal to 0.
1, if Var_Pop Y) is 0 and Var_Pop(X) is not equal to 0.
Pow(Corr(Y,X),2), if Var_Pop(Y) is more than 0 and Var_Pop(X) is not equal to 0.
REGR_AVGX
Syntax:
REGR_AVGX(<Y>, <X>)
Description:
Calculates an average of independent variables <X> for a regression line after the pairs where at least one value is NULL are excluded.
The calculation is based on the following formula: Average(X).
Returned value:
Result.
REGR_AVGY
Syntax:
REGR_AVGY(<Y>, <X>)
Description:
Calculates an average of dependent variables <Y> for a regression line after the pairs where at least one value is NULL are excluded.
The calculation is based on the following formula: Average(X).
Returned value:
Result.
REGR_SXX
Syntax:
REGR_SXX(<Y>, <X>) Description:
Performs a calculation using the following formula: Regr_Count(Y, X) * Var_Pop(X). Pairs that have at least one NULL value are ignored.
Returned value:
Result.
REGR_SYY
Syntax:
REGR_SYY(<Y>, <X>)
Description:
Performs a calculation using the following formula: Regr_Count(Y, X) * Var_Pop(Y). Pairs that have at least one NULL value are ignored.
Returned value:
Result.
REGR_SXY
Syntax:
REGR_SXY(<Y>, <X>)
Description:
Performs a calculation using the following formula: Regr_Count(Y, X) * Covar_Pop(Y, X). Pairs that have at least one NULL value are ignored.
Returned value:
Result.
RANK
Syntax:
Rank(<Order>, <HierarchyOrder>, <GroupName>)
Description:
The function defines which place the current record should take among the current group records if sorted in the order specified in the function’s parameters. Numbering starts at 1.
Parameters:
<Order>
String type. Contains statements that should have their comma-separated group records ordered in their sequence. The ordering direction is managed by Asc, Desc words. The field may also be followed by AutoOrder string which means that ordering fields specified for the referenced object should be used for reference ordering. If the sequence is not specified, the value is calculated in the grouping sequence.
<HierarchyOrder>
String type. A string that contains ordering expressions for hierarchical records.
<GroupName>
String type. Name of the group in which to calculate the function.
If omitted, calculations are carried out in the current grouping. If the calculation is performed in a table, and the parameter contains an empty string or is not specified, the value is calculated for a group string. When the data composition template is generated, the template composer replaces this name with the grouping name in the resulting template. If the grouping is not available, the function will be replaced with NULL.
Returned value:
Ordered number. If a sequence includes multiple records with identical values of ordering fields, the function will return identical values for all such records.
CLASSIFICATIONABC
Syntax:
ClassificationABC(<Value>, <GroupCount>, <PercentageForGroups>, <GroupName>)
Description:
Performs an ABC classification of each record in the group.
Parameters:
<Value>
String type. Specifies a value for which the classification should be calculated.
<GroupCount>
Type: Number. The number of groups into which to separate a value set.
<PercentsForGroups>
String type. The volume (%) of each split group, except for the last one. Listed in a row and separated by comma.
<GroupName>
String type. Name of the group in which to calculate the function. If omitted, calculations are carried out in the current grouping. If a calculation is performed on a table and the parameter includes a null string or is blank, the value is calculated for the rows grouping. When the data composition template is generated, the template composer replaces this name with the grouping name in the resulting template. If the grouping is not available, the function will be replaced with NULL.
Returned value:
Class number 1 corresponds to class A, 2 – class B, 3 – class C, etc.
Example:
ClassificationABC(SumTurnover, 3, "15, 25")
10.3.4.7. Other operations
CHOICE operation
Description:
The CHOICE operation is used to select one of the multiple values under certain conditions.
Example:
CHOICE When Sum > 1000 Then Sum Else 0 End
10.3.4.8. Rules for comparing two values
If compared values are of different types, the relationship between them is defined by priority type:
NULL (the lowest)
Boolean
Number
Date
String
reference types
Relationships between different reference types are defined based on the table reference numbers corresponding to a specific type.
If the data types are the same, their values are compared based on the following rules:
For the Boolean type, True is more than False.
For the Number type, standard rules of number comparison apply.
For the Date type, earlier dates are less than later dates.
For the String type, strings are compared according to the national database parameters.
Reference types are compared based on their values (record number, etc.).
10.3.4.9. Working with NULL value
Any operation where one of the operands is NULL will result in a NULL value.
The exceptions are:
AND will return NULL only if none of the operands is False.
OR will return NULL only if none of the operands is True.
10.3.4.10. Operation priorities
Operations have the following priorities (from the lowest to the highest priority):
OR
AND NOT
IN, IS NULL, IS NOT NULL
=, <>, <=, <, >=, >
Binary +, Binary -
*, /, %
Unary +, Unary -
10.3.4.11. Functions
EVAL
Syntax:
Eval(<Expression>,<Grouping>,<CalculationType>)
Description:
The Eval function is used to evaluate expressions within a certain grouping.
Parameters:
<Expression>
A string that contains the expression to be calculated.
<Grouping>
A string that contains the name of a grouping within which the expression is to be evaluated. If an empty string is used as a grouping name, the evaluation will be performed within the context of the current grouping. If the Overall string is used as a grouping name, the evaluation will be performed within the context of the grand total. Otherwise, the evaluation will be performed in the context of the parent grouping with this name.
<CalculationType>
A string that contains a type of calculation. If this parameter is Overall, the expression will be evaluated for all the records of the grouping. When the parameter value is Grouping, the values will be calculated for the current group record of the grouping.
Example:
Total(Sales.SumTurnover) / EVAL("Total(Sales.SumTurnover)", "Overall")
In this example, the result will be the ratio of the total by the Sales.SumTurnover field of the grouping record to the total of the same field in the entire composition.
EVALEXPRESSION
Syntax:
EvalExpression(<Expression>, <Grouping>, <CalculationArea>, <Begin>, <End>, <Sorting>, <HierarchicalSorting>,
<ProcessingSimilarOrderValues>) Description:
The function is used to evaluate expressions within a certain grouping.
The function takes filters of the groups into account but ignores hierarchical filters.
The function cannot be applied to a group in a group filter for this group. For example, in a filter of the Nomenclature group you should not use the expression EvalExpression("Total(SumTurnover)", , "Overall") > 1000.
However, this expression can be used in a hierarchical filter.
If the end record is located before the beginning one, there are considered to be no records to calculate the detailed data and aggregate functions.
When you calculate the interval expressions for overalls (the Grouping parameter is Overall), there are considered to be no records to calculate the detailed data and aggregate functions.
When the template composer generates an expression for the EvalExpression and the sorting expression contains fields that can be used in a grouping, the EvalExpression function is replaced with NULL.
Parameters:
<Expression>
String type. An expression to be calculated.
<Grouping>
String type. Contains a name of a grouping within which the expression is to be evaluated. If an empty string is used as a grouping name, the evaluation will be performed within the context of the current grouping. If the Overall string is used as a grouping name, the evaluation will be performed within the context of the grand total. Otherwise, the evaluation will be performed in the context of the parent grouping with this name.
Example:
Total(Sales.SumTurnover) / Eval("Total(Sales.SumTurnover)", "Overall")
In this example, the result will be the total of the Sales.SumTurnover field of the grouping record divided by the total of the same field in the entire composition.
<CalculationArea>
String type. The parameter may take the following values:
Overall – the expression is calculated for all group entries.
Hierarchy – the expression should be calculated for the parent hierarchical record, if any, or for the entire group if there is no parent hierarchical record.
Grouping – the expression is calculated for the current group record of the grouping.
GroupingNotResource – when the function is calculated for a group record by resources, the expression will be calculated for the first group record of the original grouping.
When the EvalExpression() function is calculated with the Grou- pingNotResource value for group records that are not grouped by resources, the function is calculated in the same manner as it is calculated with Grouping for the parameter value.
When a data composition template is created to output fields of the resource to group by to the template, data composition template composer puts an expression calculated via EvalExpression() function to the template and specifies NotResourceGroup parameter. For the remaining resources, standard resource expressions are added to the group by resource.
<Start>
String type. Specifies which record should be used to begin the portion where the aggregate expression functions should be calculated and what record should be used to retrieve field values outside of aggregate functions. It can take the following values:
First. The first record of the group should be retrieved. The word may be followed by an expression in brackets with the result used as a shift from the group beginning. The resulting value should be a positive integer. Example: First(3) means that the third value from the group beginning is retrieved.
If the first record is outside of the group, there are considered to be no records. For example, when there are 3 records and you need to retrieve First(4), it is assumed that there are no records.
Last. The last record of the group should be retrieved. The word may be followed by an expression in brackets with the result used as a shift from the group end. The resulting value should be a positive integer. For example: Last(3) means that the third value from the group end is retrieved.
If the last record is outside of the group, there are considered to be no records. For example, when there are 3 records and you need to retrieve Last(4), it is assumed that there are no records.
Previous. The previous record of the group should be retrieved. The word may be followed by an expression in brackets with the result used as a shift back from the current record of the group. For example: Previous(2) retrieves the record that is located prior to the previous one.
If the previous record is outside of the group (e.g., for the second group record you need to get Previous(3)), the first group record is retrieved.
When the previous record for a group total is retrieved, the first record is retrieved.
Next. The next record of the group should be retrieved. The word may be followed by an expression in brackets with the result used as a shift forward from the current record of the group. For example: Next(2) retrieves the record that follows the next one.
If the next record is outside of the group, there are considered to be no records. For example, when there are 3 records and you need to retrieve Next() for the third record, it is assumed that there are no records.
When the next record for a group total is retrieved, there are considered to be no records.
Current. The current record should be retrieved.
When you are retrieving for a group total, the first record is retrieved.
BoundaryValue. A record should be retrieved based on a specified value. The BoundaryValue keyword may be followed by an expression in brackets with its value used to start the portion of the first sorting field.
The first record that has its sorting field equal to or greater than the specified value will be retrieved as a record. For example, if Period is used as a sorting field, its values are 01/01/2010, 02/01/2010, 03/01/2010, and you need to retrieve BoundaryValue(DateTime(2010, 1, 15)), the record with the date 02/02/2010 will be retrieved.
<End>
String type. Specifies the record that should be the last one in the portion to be used to calculate aggregate functions of the expression. It can take the following values:
First. The first record of the group should be retrieved. The word may be followed by an expression in brackets with the result used as a shift from the group beginning. The resulting value should be a positive integer. For example: First(3) means that the third value from the group’s start is retrieved.
If the first record is outside of the group, there are considered to be no records. For example, when there are 3 records and you need to retrieve First(4), it is assumed that there are no records.
Last. The last record of the group should be retrieved. The word may be followed by an expression in brackets with the result used as a shift from the group end. The resulting value should be a positive integer. For example: Last(3) means that the third value from the group end is retrieved.
If the last record is outside of the group, there are considered to be no records. For example, when there are 3 records and you need to retrieve Last(4), it is assumed that there are no records.
Previous. The previous record of the group should be retrieved. The word may be followed by an expression in brackets with the result used as a shift back from the current record of the group. For example: Previous(2) retrieves the record that is located prior to the previous one.
If the previous record is outside of the group (e.g., for the second group record you need to get Previous(3)), the first group record is retrieved.
When the previous record for a group total is retrieved, the first record is retrieved.
Next. The next record of the group should be retrieved. The word may be followed by an expression in brackets with the result used as a shift forward from the current record of the group. For example: Next(2) retrieves the record that follows the next one.
If the next record is outside of the group, there are considered to be no records. For example, when there are 3 records and you need to retrieve Next() for the third record, it is assumed that there are no records.
When the next record for a group total is retrieved, there are considered to be no records.
Current. The current record should be retrieved.
When you are retrieving for a group total, the first record is retrieved.
BoundaryValue. A record should be retrieved based on a specified value. The BoundaryValue keyword may be followed by an expression in brackets with its value used to end the portion of the first sorting field.
The first record that has its sorting field equal to or greater than the specified value will be retrieved as a record. For example, if Period is used as a sorting field, its values are 01/01/2010, 02/01/2010, 03/01/2010, and you need to retrieve BoundaryValue(DateTime(2010, 1, 15)), the record with the date 02/01/2010 will be retrieved.
<Sorting>
String type. Lists comma-separated expressions that describe ordering rules. If not specified, ordering is performed in the same way as in the group for which the expression is evaluated. The Asc (to sort by ascending order) or Desc (to sort by descending order) and AutoOrder (to order reference fields by the fields to be used to sort a referenced object) keywords can be used after each expression. AutoOrder can be used both with the Asc and Desc keywords.
<HierarchicalSorting>
String type. Similar to Sorting parameter. Used to sort hierarchical records. If missing, the template composer generates a sorting based on the value in the Sorting parameter.
<ProcessingSimilarOrderValues>
String type. Sets the rule to define a previous or a next record if there are several records with the same ordering value:
Separately – means that a sequence of sorted records is used to determine the previous and next records. This is the default value.
Together – means that the previous and next records are defined based on the sorting expression values.
For example, if a retrieved sequence is sorted by date:
|
¹ |
Date |
Full name |
Value |
|
1 |
January 01, 2001 |
M. Ivanov |
10 |
|
2 |
January 02, 2001 |
S. Petrov |
20 |
|
3 |
January 02, 2001 |
R. Sidorov |
30 |
|
4 |
January 03, 2001 |
S. Petrov |
40 |
If the parameter is set to Separately, then:
○ Record 2 will serve as the previous one for record 3.
○ If a calculation fragment is defined as Current, Current (with parameters Begin and End respectively), this fragment will only contain one record (which is record 2) for record 2. Expression EvalExpression("Total(Value)", , , Current, Current) will be equal to 20.
If the parameter is set to Together, then:
○ Record 1 will serve as the previous one for record 3.
○ If a calculation fragment is defined as Current, Current (with parameters Begin and End respectively, this fragment will contain records 2 and 3 for record 2. Expression EvalExpression("Total(Value)", , , Current, Current) will be equal to 50.
If a parameter value equal to Together is specified, do not specify offsets for positions First, Last, Previous, Next in Begin and End parameters.
Example:
If an amount with accumulation needs to be calculated, use the following expression:
EvalExpression("Total(SumTurnover)", , , "First", "Current")
If you need to obtain a grouping value in the previous line, use the following expression:
EvalExpression ("Rate", , , "Previous")
EVALEXPRESSIONWITHGROUPARRAY
Syntax:
EvalExpressionWithGroupArray (<Expression>, <GroupFieldsExpressions>, <RecordsFilter>, <GroupFilter>)
Description:
The function retrieves an array with every item containing the result of calculating the expression for the group by the specified field.
When the template composer generates a template, it converts function parameters into data composition template field terms. For example, the Contractor field will be converted into DataSet.Contractor.
When the template composer generates expressions to output a custom field with an expression containing only EvalArrayWithGroupArray(), it will generate the required expression so that the data display presentations are sorted. For example, for a custom field with the expression:
EvalExpressionWithGroupArray("Total(SumTurnover)", "Contractor")
the template composer will generate the following expression to be output:
JoinStrings(Array(Sort(EvalExpressionWithGroupValueTable ("Presentation(Total(DataSet.SumTurnover)),
Total(DataSet.SumTurnover)", "DataSet.Contractor"), "2")))Parameters:
<Expression>
String type. An expression to be calculated. A string, for instance Total(SumTurnover).
<GroupFieldsExpression>
String type. Group field expressions are comma-separated expressions of the group fields. For example: Contractor, Batch.
<RecordsFilter>
String type. An expression that describes a filter applied to detailed records.
For example, DeletionMark = False.
<GroupFilter>
String type. An expression that describes a filter applied to group records.
For example: Total(SumTurnover) > &Parameter1.
Example:
Maximum(EvalExpressionWithGroupArray ("Total(SumTurnover)", "Contractor")).
EVALEXPRESSIONWITHGROUPVALUETABLE
Syntax:
EvalExpressionWithGroupValueTable (<Expressions>, <GroupFi- eldsExpressions>, <RecordsFilter>, <GroupFilter>)
Description:
The function retrieves a table of values with every row containing the result of calculating the expressions for the group by the specified field.
When the template composer generates a template, it converts function parameters into data composition template field terms. For example, the Contractor field will be converted into DataSet.Contractor.
When the template composer generates expressions to output a custom field with an expression containing only EvalArrayWithGroupValueTable(), it will generate the required expression so that the data display presentations are sorted. For example, for a custom field with the expression:
EvalExpressionWithGroupValueTable ("Contractor, Total(SumTurnover)", "Contractor")
the template composer will generate the following expression to be output:
JoinStrings(GetPart(Sort(EvalExpressionWithGroupValueTable ("DataSet.Contractor, dataSet
.ContractorPresentation, Total(DataSet.SumTurnover), Presentation(DataSet.SumTurnover),
DataSet.SortingField", "DataSet.Contractor"), "5, 1, 3"), "2, 4"))Parameters:
<Expressions>
String type. The expressions to be calculated. The string may list multiple comma-separated expressions. Each expression may be followed by an optional AS keyword and the name of a value table column. For example: Contractor, Total(SumTurnover) AS SalesVolume.
<GroupFieldsExpression>
String type. Group field expressions are comma-separated expressions of the group fields. For example: Contractor, Batch.
<RecordsFilter>
String type. An expression that describes a filter applied to detailed records.
For example, DeletionMark = False.
<GroupFilter>
String type. An expression that describes a filter applied to group records. For example: Total(SumTurnover) > &Parameter1.
Example:
EvalExpressionWithGroupValueTable ("Contractor AS Contractor, Total(SumTurnover) AS SalesVolume", "Contractor")
The result of this function is a table of values that has columns named Contractor and SalesVolume that will contain contractors with their respective volumes of sales.
LEVEL
Description:
This function is intended to retrieve the current record level.
Example:
LEVEL()
LEVELINGROUP
Description:
The function is used to retrieve the level of an entry in relation to the group root.
Example:
LEVELINGROUP()
VALUEISFILLED
Description:
Returns True, if the value differs from the value of another default type, differs from NULL, from an empty link, and the Undefined value. NULL value is checked for logical values. Strings are checked to verify whether they contain any non-spacing characters.
SERIALNUMBER
Description:
This function retrieves the next sequence number.
Example:
SERIALNUMBER()
GROUPSERIALNUMBER
Description:
This function returns the next sequence number in the current grouping.
Example:
GROUPSERIALNUMBER()
FORMAT
Description:
This function retrieves a formatted string of the transferred value. The format string defined in compliance with the 1C:Enterprise format string.
Parameters:
Value
Format string Example:
FORMAT(Invoices.SumDoc, "NFD=2")
BEGINOFPERIOD
Description:
This function is intended to extract a specific date from a given date.
Parameters:
Expression of type Date.
Type of period – a string that contains one of the following values: Minute, Hour, Day, Week, Month, Quarter, Year, Decade, HalfYear.
Example:
BEGINOFPERIOD(DateTime(2002, 10, 12, 10, 15, 34), "Month")
Result:
01.10.2002 0:00:00
ENDOFPERIOD
Description:
This function is intended to extract a specific date from a given date.
Parameters:
Expression of type Date.
Type of period – a string that contains one of the following values: Minute, Hour, Day, Week, Month, Quarter, Year, Decade, HalfYear.
Example:
ENDOFPERIOD(DateTime(2002, 10, 12, 10, 15, 34), "Week")
Result:
13.10.2002 23:59:59
DATEADD
Description:
This function is used to add a value to a date.
Parameters:
Expression of type Date.
Type of increment – a string that contains one of the following values: Second, Minute, Hour, Day, Week, Month, Quarter, Year, Decade, HalfYear.
Size – specifies the value of date increment. Number type. Fractions are ignored.
Example:
DATEADD(DateTime(2002, 10, 12, 10, 15, 34), "Month", 1)
Result:
12.11.2002 10:15:34
DATEDIFF
Description:
This function is intended to obtain the difference between two dates.
Parameters:
Expression of type Date.
Expression of type Date.
Type of difference – one of the values: Second, Minute, Hour, Day, Month, Quarter, Year.
Example:
DATEDIFFERENCE(DATETIME(2002, 10, 12, 10, 15, 34), DATETIME(2002, 10, 14, 9, 18, 06), "DAY")
Result:
2
CURRENTDATE
Description:
Returns system data. When a composition template is composed in all the expressions present in the composition, the CurrentDate() function is replaced with the current date value.
Example:
CURRENTDATE()
SUBSTRING
Description:
This function extracts a substring from a string.
Parameters:
An expression of string type.
The position of the character where the substring starts.
The length of the extracted substring.
Example:
SUBSTRING(Contractors.Address, 1, 4)
STRINGLENGTH
Description:
This function defines the string length. The parameter is a string type expression.
Example:
STRINGLENGTH (Contractors.Address)
YEAR
Description:
This function extracts a year from a Date value. The only parameter is an expression of type Date.
Example:
YEAR(Invoice.Date)
QUARTER
Description:
This function extracts a quarter number from a Date value. As a rule, a quarter number is between 1 and 4. The only parameter of the function is an expression of type Date.
Example:
QUARTER(Invoice.Date)
MONTH
Description:
This function is intended to obtain a month number from a Date value. As a rule, a month number is between 1 and 12. The only parameter of the function is an expression of type Date.
Example:
MONTH(Invoice.Date)
DAYOFYEAR
Description:
This function retrieves the day of the year from a Date value. The day of the year is normally in the range from 1 to 365 (366). The only parameter of the function is an expression of type Date.
Example:
DAYOFYEAR(Invoice.Date)
DAY
Description:
This function retrieves the day of the month from a Date value. As a rule, a day number is between 1 and 31. The only parameter of the function is an expression of type Date.
Example:
DAY(Invoice.Date)
WEEK
Description:
This function retrieves the week number in a year from a Date value. Weeks of the year are numbered starting with 1. The only parameter of the function is an expression of type Date.
Example:
WEEK(Invoice.Date)
WEEKDAY
Description:
This function retrieves the day of the week from a Date value. The day of the week is normally in the range from 1 (Monday) to 7 (Sunday). The only parameter of the function is an expression of type Date.
Example:
WEEKDAY(Invoice.Date)
HOUR
Description:
This function retrieves the hour (in 24-hour format) from a Date value. As a rule, the hour of the day is between 0 and 23. The only parameter of the function is an expression of type Date.
Example:
HOUR(Invoice.Date)
MINUTE
Description:
This function retrieves the minute number from a Date value. As a rule, the minute of the hour is between 0 and 59. The only parameter of the function is an expression of type Date.
Example:
MINUTE(Invoice.Date)
SECOND
Description:
This function retrieves the second in a minute from a Date value. The number of second is between 0 and 59. The only parameter of the function is an expression of type Date.
Example:
SECOND(Invoice.Date)
CAST
Description:
This function extracts a type from an expression that can contain a compound type. If the expression contains a type other than the required one, the NULL is returned.
Parameters:
Expression transformed
Type – a string that contains a type string. For example, Number, String, etc. In addition to primitive types, the string can also contain a table name.
In this case the function attempts to cast to the table reference.
Example:
CAST(Data.Attribute1, "Number(10,3)")
ISNULL
Description:
This function returns the second parameter value if the first parameter is NULL.
Otherwise, the first parameter value is returned.
Example:
ISNULL(Total(Sales.SumTurnover), 0)
PRESENTATION
Syntax:
Presentation(<Expression>) Description:
This function retrieves the string presentation of the non-primitive type value delivered. The value itself is returned for primitive values.
If an array is transferred as a parameter, the function returns a string containing string presentations of all the array items separated by ";". If a value table is transferred as a parameter, the function returns a string that contains string presentations of all value table strings, and cell presentations of each row are separated by ";", while the rows are separated with a line feed character. If an item has an empty string presentation, a string reading <Empty value> is displayed instead of its presentation.
Example:
Presentation(Contractor)
STRING
Syntax:
String(<Expression>)
Description:
If an array is transferred as a parameter, the function returns a string containing string presentations of all the array items separated by ";". If a value table is transferred as a parameter, the function returns a string that contains string presentations of all value table strings, and cell presentations of each row are separated by "; ", while the rows are separated with a line feed character. If an item has an empty string presentation, a string reading <Empty value> is displayed instead of its presentation.
Example:
String(SaleDate)
ACOS
Syntax:
ACos(<X>) Description:
Calculates the arccosine value.
ASIN
Syntax:
ASin(<X>) Description:
Calculates the arcsine value.
ATAN
Syntax:
ATan(<X>) Description:
Calculates the arctangent value.
COS
Syntax:
Cos(<X>)
Description:
Calculates the cosine value.
SIN
Syntax:
Sin(<X>)
Description:
Calculates the sine value.
TAN
Syntax:
Tan(<X>)
Description:
Calculates the tangent value.
EXP
Syntax:
Exp(<X>)
Description:
Calculates e raised to the power of X.
LOG
Syntax:
Log(<X>)
Description:
Calculates a natural log value.
LOG10
Syntax:
Log10(<X>) Description:
Calculates a common log value.
POW
Syntax:
Pow(<X>, <Y>) Description:
Calculates X raised to the power of Y.
SQRT
Syntax:
Sqrt(<X>) Description:
Calculates a square root value.
ROUND
Syntax:
Round(<Expression>, <CharacterCount>) Description:
Rounds off the Expression value to CharacterCount after the comma.
INT
Syntax:
Int(<Expression>) Description:
Calculates the cosine value.
VALUETYPE
Syntax:
ValueType(<Expression>)
Description:
Calculates a type of expression transferred as a parameter.
Returned value:
A value of type Type.
10.3.4.12. Common module functions
A data composition mechanism expression may contain function calls of global common modules of the configuration and nonglobal common modules with the Client (ordinary application) (if a standard application is used) or Server (if a managed application is used) property set. You do not need to use additional syntax to call these functions.
BriefDescription(Doc.Ref, Doc.Date, Doc.Number)
This example will call the BriefDescription() function from a common module of the configuration.
Note that you can only use shared module functions if you specify the corresponding data composition processor parameter.
Moreover, shared module functions cannot be used in custom field expressions.
10.3.5. Data Composition Schema Wizard
The data composition schema wizard is a 1C:Enterprise script DataCompositionSchemaWizard object intended for visual design of the data composition schema. Moreover, the data composition schema wizard is used in the Designer to edit the data composition schema.
For query data sets, the wizard automatically obtains nested data sets from the query text and represents them as data set fields (nested data set). For object data sets, the wizard supports addition of nested data set fields.

Fig. 238. Addition of a New Data Set
An example of how the data composition schema wizard window opens and the obtained composition schema is serialized in XML is shown below:
Procedure ReportEditorCommandBar (Button)
Wizard = New DataCompositionSchemaWizard;
Wizard.SetSchema(GetDataCompositionSchema());
Wizard.Edit(ThisObject);
EndProcedure
Procedure ChoiceProcessing(SelectionValue, Source)
If TypeOf(Source) = Type("DataCompositionSchemaWizard") Then
DataCompositionSchema = Source.GetSchema();
XMLWriter = New XMLWriter;
XMLWriter.SetString();
XDTOSerializer.WriteXML(
XMLWriter, DataCompositionSchema,
"dataCompositionScheme",
"http://v8.1c.ru/8/data-composition-system/scheme");
FormElements.DataCompositionSchemaText.SetText(XMLWriter.Close());
EndIf;
EndProcedureWork with the data composition schema is divided into the following stages:
Editing data sets
Editing data set fields
Editing data set links
Editing calculated fields
Editing resources
Editing parameters
Editing templates
Editing nested settings
Editing data composition system settings
10.3.5.1. Editing Data Sets
The data composition system supports editing for the following objects:
Query data set
Object data set
Union data set
Query fields
When a data set is added, a name and data source are automatically generated for it (if a data source does not exist).
A data composition schema data set field that represents a nested data set can be described in a query and an object data set.
The {SELECT} and {WHERE} clauses in an object data set query can include nested tables.
SELECT
GoodsReceipt.Date,
GoodsReceipt.Number,
GoodsReceipt.Vendor,
GoodsReceipt.Warehouse,
GoodsReceipt.Goods.(
LineNumber,
Product,
Price,
Count,
Sum
)
{SELECT
Date,
Number,
Vendor.*,
Warehouse.*,
Goods.(
LineNumber,
Product.*,
Price,
Count,
Sum
)}
FROM
Document.GoodsReceipt AS GoodsReceipt
{WHERE
GoodsReceipt.Date,
GoodsReceipt.Number,
GoodsReceipt.Vendor.*,
GoodsReceipt.Warehouse.*,
GoodsReceipt.Goods.(
LineNumber,
Product.*,
Price,
Count,
Sum
)}Code fragments in bold in the above example describe nested table fields that are available for setup.
Editing Query Data Set
Editing a query data set comprises generating a data query. You can use the query wizard or edit query text directly in the data composition schema wizard window (see fig. 239).
If the Autofill flag is set, the data composition system automatically fills the data composition system fields based on the created query.

Fig. 239. Query Data Set
Editing Object Data Set
Editing an object data set comprises adding/editing the name of the object that contains the data and adding/editing fields and groups.

Fig. 240. Object Data Set
Editing Union Data Set
Editing a union data set comprises editing merged fields that are in the list of fields subordinate to the data set. The created query and object data sets can be dragged and dropped in a union data set.

Fig. 241. Union Data Set
10.3.5.2. Editing Data Set Fields
When editing fields, the following can be specified:
Field header
Field accessibility restriction
Attribute field accessibility restriction
Role for the field
Field presentation
Order expressions
Hierarchy check methods (data set and parameter)
Field value type
Field appearance
Please note that the field's role, presentation order expression, parameter, value type and appearance can only be edited at the top level of the data set hierarchy.
If a data set field has no header, the data composition system attempts to generate the header on the basis of the query field synonym. If no synonym can be obtained for the field, the field data path is used as the header; however, it is first supplemented by white spaces using the name-to-synonym conversion algorithm.
Synonyms are only retrieved for the query fields that either have no alias or have an alias that is different from the default alias.
The following method is used to obtain synonyms for a query field:
If the query has no unions:
○ If the query field expression includes a single field, the synonym is retrieved from this field;
○ If the field expression is an aggregate function of a single field, the field synonym is retrieved from this field. For other expressions, obtaining a synonym is considered impossible.
If the query has unions:
○ All unions are searched for the field that allows obtaining a synonym which is then used as the field synonym. If no field is found, obtaining a synonym is considered impossible.
The data composition schema wizard includes an additional column with a check box that indicates that the field header is manually set. The check box is cleared by default if the field has no header.
When filling fields based on a query, the wizard auto-fills headers for the fields that either cannot obtain a synonym or have an alias that is different from the default alias. Thus, the check box is auto-selected for these fields.
If this check box is deselected, the Title column displays the header to be displayed to the user. However, the field header is not actually filled in this case. The Title column for the fields with the deselected check box is not editable and highlighted as unavailable.
If the developer wants to change the header, he/she can enable the check box; the field header is filled based on the text previously displayed in the Title column. When the check box is cleared, the wizard clears the query text and displays autogenerated text in the header.
The field role is initially defined in the query, but can be changed in a separate dialog box (see fig. 242).
The account field requires am explicit reference to the account type in the Type parameter.
The dimension field can have a path to the parent dimension data indicated in the Dimension parameter.
If the Ignore NULL values flag is set, it means the result will not include group records for the field if its value is NULL.
The resulting data set always includes fields with the Required flag set if at least one field of the data set is used in the settings. For example, if you want to obtain split balance for extra dimensions, but the ExtDimensions field is not used in the query, the balance is not split.

Fig. 242. Field Role
The field's order expression, value type and appearance can also be edited in a separate dialog box.
10.3.5.3. Editing Data Set Links
If multiple top-level data sets exist, it is possible to set up links between them by one or several fields.
Fig. 243. Data Set Links
Data sets act as link sources and destinations. The source and destination expressions are data set fields.
10.3.5.4. Editing Calculated Fields
The Calculated fields tab allows creating and editing the following properties/characteristics of calculated fields:
Data path
Expression
Header
Accessibility restriction
Presentation expression
Order expressions
Value type
Appearance
Available values
Order expressions are edited in a separate dialog box.
10.3.5.5. Editing Resources
Resource calculation is available for all fields of all data sets and for calculated fields. The left table box displays a list of available and unused fields. The right table box displays the fields used for generating totals and calculation expressions.
Fig. 244. Editing Resources
By default the Sum function is set for numeric fields and the Count function – for non-numeric fields. Use the >> button to add all fields of the Number type to the resources. You can also enter multiple rows for a single resource. When the template composer obtains an expression for a resource, it uses information about the target group and displays the corresponding expression.
In the Calculate by… column edit dialog, for fields for which hierarchical grouping is possible, strings with a field name and Hierarchy keyword are added. The expression will be used for hierarchical grouping records for the field specified before the keyword. When a group is selected in the context of which a resource can be calculated, you can simultaneously select both a usual and a hierarchical field.
If a resource can only be calculated for a certain group (i.e. its Calculate by… column contains at least one group), then this resource is output to the result for this group and its nested groups only.

Fig. 245. Calculating resources by the group fields
10.3.5.6. Editing Parameters
Editing parameters includes:
editing parameter name
editing header
editing available parameter types and values
defining a value and parameter value list accessibility
defining an expression
defining a parameter as an available data composition setting field
accessibility restriction
determine whether the parameter is required
the parameter usage attribute
setting edit parameters

Fig. 246. Editing Parameters
If a parameter value is undefined, it is seen as a zero reference to the set type. Parameters can include predefined data and enumerations (the Designer mode).
The Available values column is used to edit values that can be selected by the user as data composition schema parameters. If the List of values is available check box is selected, it means multiple parameter values can be used.
NOTE
If the StandardPeriod parameter type is used, please note that the start and end dates of a standard period also contain time values. The start date contains
00:00:00 as its time value, while the end date contains 23:59:59. Thus, the BEGINOFPERIOD and ENDOFPERIOD functions are no longer required in a query.
Let's consider an example of using a required data composition schema parameter: assume that the Organization parameter is required for a report. In the data composition schema, for the Organization parameter the Usage property is set to Always, and Disallow incomplete values is set to True.
When working with a report, the Usage field is not available for a user, and any unfilled value is shown as usual (wavy red line). If a user does not enter a parameter value and runs the report, he will get the message saying that he must enter the parameter value.
10.3.5.7. Editing Templates
Add templates by pressing the Add Template button on the command bar.

Fig. 247. Template Editor
You can choose one of three template types:
Field template
Group template
Group header template
Table resources template
Group name and fields and template types can be set for a group or group header template.
For a table resource template, you can specify templates for two groups that include this template.
The table box Area column specifies template area coordinates in a spreadsheet document.
Spreadsheet document areas can be edited using the properties panel, called by pressing Alt + Enter. Both the appearance and the cell content and drill down parameter are editable.
A template can be edited in any language supported in the system. If a parameter or a template is assigned to a spreadsheet document cell, parameters are added to the template and displayed in the Parameter name column of the Template Parameters table box. Template parameter expressions can be edited. When a template is loaded, its areas are separated by empty rows.
10.3.5.8. Nested Schemas
The Nested schemas tab allows creating and editing nested data composition schemas. Nested schemas edited by the data composition schema wizard can act as a schema.

Fig. 248. Nested Schemas
10.3.5.9. Settings
A data composition schema contains default data composition settings that can be specified by the developer.

Fig. 249. Data Composition Schema Settings Editor
The Auto position of resources report settings control how resource fields are displayed:
Do not use – in this case resources are shown in the order in which fields are listed in the Selected fields tab.
After all fields – in this case resources are displayed after all fields.
A group (or a table group) has the Grouping use case parameter that controls how additional information is displayed after resource fields. If this parameter is not set or is set to Auto, the group is responsible for showing detailed records.
If this parameter is set to Additional information for a column group, the result table in this column will show one column with the fields listed in the Selected fields tab of this group that are available for display in a row group. If group fields are set for the column group, an error will occur when the data composition template is generated. The same applies for a row group, except that one row is shown instead of a column.
For example, Nomenclature is shown in table rows. And warehouses are shown in table columns. A report on inventory at warehouses is generated. It is necessary to show the nomenclature article after columns with the inventory. To do this, add a table group to the columns without group fields and set the Grouping use case parameter to Additional information in group settings. In the Selected fields tab, specify the Nomenclature.Article field.
When such a group is shown outside the table, all fields available in the group are displayed.
Thus, if a report contains a group with multiple nested groups, you can use a group with the Grouping use case parameter set to Additional information to display parent group data between the groups.
The following parameters are ignored for groups with the Additional information usage option:
Group Fields Location – field titles shown in a group are always displayed at the beginning of a row/column.
Records number.
Records percent.
Totals placement.
Grouping field placement.
Grouping placement.
Grand totals placement.
When the data template is composed, if a group with the Additional information usage option uses a field that is not available in the group or a table and it is not available for any group, an exception is called.
Nested Fields
The system automatically generates nested fields for numeric resources. These fields are calculated by the system and simplify generation of different indicators, for example, a resource percentage of a resource values sum in all report data.
These fields include:
% in hierarchical group
Identifier:
PercentInHierarchy Description:
This field shows the resource percentage in the current hierarchical group.
When the field is shown outside the table, the value is 100%.
% in a column or a point hierarchical group
Identifier:
PercentInColumnOrPointHierarchy Description:
This field shows the current cell resource value percentage of the resource total value in the current hierarchy level of the current column/point group. When the field is shown outside the table, the value is % in hierarchy group.
% in a row or a series hierarchical group
Identifier:
PercentInRowOrSeriesHierarchy Description:
This field shows the current cell resource value percentage of the resource total value in the current hierarchy level of the current row/series group. When the field is shown outside the table, the value is 100%.
% in a group
Identifier:
GroupPercent Description:
This field shows the current cell resource value percentage of the resource total value in the current group. When the field is shown outside the table, the value is 100%.
% in a column or a point group
Identifier:
ColumnOrPointGroupPercent Description:
This field shows the current cell resource value percentage of the resource total value in the current column/point group. When the field is shown outside the table, the value is 100%.
% in a row or a series group
Identifier:
RowOrSeriesGroupPercent Description:
This field shows the current cell resource value percentage of the resource total value in the current row/series group. When the field is shown outside the table, the value is % in group.
% in a column or a point
Identifier:
ColumnOrPointPercent Description:
This field shows the current cell resource value percentage of the resource total value per column/point. When the field is shown outside the table, the value is % total.
% in a row or a series
Identifier:
RowOrSeriesPercent Description:
This field shows the current cell resource value percentage of the resource total value per row/series. When the field is shown outside the table, the value is 100%.
% total
Identifier:
OverallPercent Description:
This field shows the current cell resource value percentage of the resource total value in the table. When the field is shown outside the table, the value is 100%.
System Fields
The system generates a special system field group in the list of selected fields. These are used to determine the record sequence number both for the whole report and a separate group. Note that system fields are not included in the list of fields with auto fields when expanding, so they have to be added manually.
Ser. #
Identifier:
SystemFields.SerialNumber Description:
Shows the row sequence number in the given report. Numeration always starts from 1.
# in group
Identifier:
SystemFields.GroupSerialNumber Description:
Shows the row sequence number in the current group. Numeration always starts from 1.
Level
Identifier:
SystemFields.Level Description:
Shows the current record's level. Numeration always starts from 1.
Level in group
Identifier:
SystemFields.LevelInGroup Description:
Shows the current record's level relative to the group. Numeration always starts from 1.
Parameter Fields
There is a special group in selected fields, Parameters, that can be used to add data composition schema parameters with Include in available fields checked to a report.
10.3.6. Data Composition Variant Settings
In a data composition schema, multiple settings variants can be defined. A settings variant is a set of report settings picked out by the developer for some purpose. These settings variants are stored in the data composition schema.
For example, for a Sales Trends report, one report variant may be a chart showing product sales by periods and another variant may be a spreadsheet report representing product sales by customers. Each report variant has its own set of custom settings (see page 1-610).
When a data composition schema is used for the report, settings variants described in the schema are presented to the user as standard report variants.
The system enables the user to create a new report variant directly in the 1C:Enterprise mode. This option is recommended to advanced users only. In this case the new report variant is saved in the reports variants storage that is used by other users to load the required variant. For a description of the reports variants storage see page 1-223.
The configuration comparison and merge mechanism (see page 2-1071) can be used to partially compare and merge settings.
The data composition schema can be loaded from XML using the standard 1C:Enterprise script tools.
10.3.6.1. Structure of Data Composition Settings Variant
Structure is a settings framework. It defines the mutual position of their main items.
The settings structure is accessible through the Structure property of the DataCompositionSettings object. The settings structure items can be:
Groups
Tables (DataCompositionTable)
Charts (DataCompositionChart)
Nested settings objects (DataCompositionNestedObjectSettings)
Group
To implement a group, three different data types are used in the settings structure:
Groups (DataCompositionGroup)
Table groups (DataCompositionTableGroup)
Chart groups (DataCompositionChartGroup)
Use of three types is explained by the requirement to implement limitations on the mutual position of items in the structure tree: tables and plans cannot contain anything except groups. Correspondingly, all group objects have a similar object model; they are distinguished by types of nested value collection and contents of output parameters.
Group Fields
A set of fields used for grouping is described in the DataCompositionGro- upFields object. The Items property of this object contains a group field collection consisting of DataCompositionGroupField objects.
NOTE
When grouping by the period field, a parent period field which is not an additional period is automatically added to the group if grouping by this parent period field was not performed in the parent groups.
For example, if grouping is performed by the Recorder field, then the SecondPeriod field is automatically added to the group.
Creation of groups by period field attributes is not allowed.
Autogroup Field
An auto-field is converted to a set of group fields before use.
The procedure used to generate the set is described below. The selected used fields meeting the following criteria are chosen:
The fields are available to be used in the group fields.
They are not resources.
They are not dependent on other selected fields.
They are not dependent on the existing group fields.
If a field is already included in the group field data, it is not added again.
Table
A table description in the settings structure is performed using the DataCompositionTable object.
Chart
A chart description in the settings structure is performed using the DataCompositionChart object.
Nested Object
A nested object description in the settings structure is performed using the DataCompositionNestedObjectSettings object.
The Name property is implemented for the object. This property is used to identify a nested report within the generated data composition template.
10.3.6.2. Properties of Data Composition Settings
Selection
A set of fields output as a result of composition. It is described using the DataCompositionSelectedFields object. The Items property of this object contains a collection of selected fields consisting of DataCompositionSe- lectedField objects.
Selected Field Group
It is used to group fields. It is described using the DataCompositionSelec- tedFieldGroup object.
Auto-Selected Field
An auto-field is converted to a set of selected fields before use. The list of fields in the set depends on what structure item owns the expanded auto-field and what part of the structure this item is located at. The system tabs through all the report structure parent items for each item and selects resource and fields using the following rules:
For a group or table group the following replaces an auto-field:
○ All the used fields of the group that are available for used in the selected fields;
○ Fields that represent attributes of the group fields; ○ Resources of parent items.
IMPORTANT!
The system only tabs through groups with the Elements or Hierarchy type.
For chart groups, resources are not selected; instead, all settings structure parent items are tabbed through and group fields are selected from the selected item fields if they have a Hierarchy only group.
For Detailed records groups (groups, table groups, plan groups), all used fields are selected from the main selected fields of the settings that own a particular group, with the exception of the fields included in upper-level groups and their attributes. If this group is Hierarchy only, its fields and attributes are used by the system to generate a set of combo boxes. For chart groups, resources are not selected, too.
For Additional information-type fields, fields are added to the selected fields (not resources) that are available in a group or a parent group, a table and in any group from the opposite axis.
For a diagram, the autoselection field is replaced with all resources stated above.
For charts, an auto-selection field is replaced by a resource that is first encountered in the tabbing procedure described above.
For tables, an auto-selection field is converted to a set of resources used by parent items.
NOTE
If a field is already included in the selected fields, it is not added again.
Fields are added to the set in the following order: first, fields of the group's own fields (for groups), then fields from the global settings (for Detailed records groups) and, finally, resources and fields from the parent items.
Filter
It is used to filter records included in the composition result. It can also be used to filter records with applied appearance (conditional appearance) and to create user combo boxes.
It is described using the DataCompositionFilter object. The Items property of this object contains a collection of filter items consisting of DataCompositionFilterItem objects.
Filter Item Group
It is used to group filter items and order the result data. It is described using the DataCompositionFilterItemGroup object.
Order
It describes how to order records output in the result. It represents a DataCompositionOrder object. The Items property of this object contains a collection of order items consisting of DataCompositionOrderItem objects.
Auto-Order Item
An auto-order item is converted to a set of order items before use.
The following rules are used to generate the set: resources are added unconditionally, while non-resource fields are only selected if they are group field attributes or the group field itself (all fields are added to the set for detail records). Group fields that are not specified in the global order are added to the end of the order. If a field is already included in the selected order, it is not added again.
Conditional Appearance
It describes how to format different result fields. It represents the DataCompositionConditionalAppearance object. The Items property of this object contains a collection of order elements consisting of DataCompositionConditionalAppearanceItem objects.
The Format and Text parameters are edited as multilingual in the data composition appearance of the data composition wizard.
For an element of conditional appearance, you can specify to which areas such conditional appearance should be applied.
To a field output in the grouping
To a field output in a hierarchical grouping
To a field output in total
To field headers
To a report header area
To the area where report parameters are output
To the area where filter values are output
Appearance Fields
These are fields with applied appearance. They are described using the DataCompositionAppearanceFields object. The Items property of this object contains a collection of appearance fields consisting of DataCompositionAppearan- ceField objects. If no fields are indicated, appearance is applied to the entire area.
Output Parameters
Output parameter values define object appearance. Inheritance is supported for some parameters. It means the output parameter collection for an item can contain parameters that do not belong to the item, but are used in items that can be inserted in a subordinate settings structure.
Data Parameters
Data parameter values are usually used in queries for selection filtering.
User Fields
User fields allow the user to extend a set of the used available fields by defining custom expressions or variant sets with the condition of using a specified variant.
User fields are described using the DataCompositionUserFields object. The Items property of this object contains a collection of user fields consisting of two object types:
Expression field (DataCompositionUserFieldExpression object)
Case field (DataCompositionUserFieldCase object)
The system defines the field type automatically based on its properties.
User Field Variants
It is a description of alternatives set that defines case field value. They are described using the DataCompositionUserFieldsCaseVariants object.
The Items property of this object contains a collection of user case field variants consisting of DataCompositionUserFieldsVariant objects.
Work with Auto-Fields
If a settings structure item contains DataCompositionAutoGroupField, DataCompositionAutoSelectedField and DataCompositionAutoOrderItem auto-fields, they are converted as follows:
DataCompositionAutoGroupField
DataCompositionAutoSelectedField
DataCompositionAutoOrderItem
10.3.6.3. Available Objects
Available objects are a set defining the objects that can be used as nested objects in composition. Nested reports are an example of these objects.
10.3.6.4. Available Fields
Available fields are a set of fields that can be used for data composition settings and are identified and processed correctly at the subsequent composition stages. Available fields have different applications. The following field collections can be identified:
Fields for selection (SelectionAvailableFields property)
Group fields (GroupAvailableFields property)
Order fields (OrderAvailableFields property)
Data parameter fields (DataParametersAvailableFields property)
Filter fields (FilterAvailableFields property)
Structure item filter fields used for all structure items except the top-level (StructureItemsFilterAvailableFields property)
Additional filter fields used for conditional appearance (AdditionalFil- terAvailableFields property)
All the listed properties contain value collections with DataCompositionAvailableField objects.
In the data composition schema wizard and the report data composition schema settings, available fields are ordered as follows: first, alphabetically ordered non-resource fields, then alphabetically ordered resource fields. System folders are the last to be displayed in the list.
Available Filter Field
Available fields of a special type are designed for orders. They have the same properties as standard available fields, but also provide sets of available comparison types and available field values required to generate order items correctly.
10.3.6.5. Data Composition Settings Composer
The settings composer is represented by the 1C:Enterprise script DataCompositionSettingsComposer object. This object is intended to link data composition settings and the data composition schema. The source of available settings for a settings editor is built on basis of the data composition schema.
10.3.7. User Settings of Data Composition System
Certain settings can be marked for the user to edit them in a separate form. This mechanism is known as user settings.
Composition supports both user and complete settings. User settings are added on to the complete settings, thus forming settings that are actually executed.
10.3.7.1. User Settings Object Model
User settings can be used to edit the following objects:
DataCompositionFilter
DataCompositionFilterItem
DataCompositionFilterItemGroup
DataCompositionOrder
DataCompositionSelectedFields
DataCompositionConditionalAppearance
DataCompositionConditionalAppearanceItem
DataCompositionSettingsParameterValue
DataCompositionGroup
DataCompositionTableGroup
DataCompositionChartGroup
DataCompositionTable
DataCompositionChart
NestedDataCompositionSchema
DataCompositionStructureItemCollection
DataCompositionTableStructureItemCollection DataCompositionChartStructureItemCollection
These objects have the following properties:
UserSettingID – identifies the user setting object. If this property is set, the object is considered a user object and must be edited in the user settings. If a setting is interactively marked as a user setting, the system auto-generates a unique ID and fills this property with the ID's string presentation.
UserSettingPresentation – is a string used to display a presentation in the user settings. The schema wizard allows the user to enter presentations in multiple languages.
ViewMode – is used to define quick settings. For details on this feature see the sections below.
In the object model, user settings are represented by a special DataCompositionUserSettings object. This object has the Items property. It is a collection of user settings items. The following objects are valid:
DataCompositionFilter
DataCompositionFilterItem
DataCompositionFilterItemGroup
DataCompositionOrder
DataCompositionSelectedFields
DataCompositionConditionalAppearance
DataCompositionConditionalAppearanceItem
DataCompositionParameterValue
DataCompositionGroup
DataCompositionTableGroup
DataCompositionChartGroup
DataCompositionTable
DataCompositionChart
DataCompositionNestedObjectSettings
DataCompositionSettingStructure
10.3.7.2. Setup of User Settings Items
A settings item can be marked as a user item in the user item setup form invoked by the Custom settings item property command.

Fig. 250. Open a User Setting
The user item setup form can be used to specify that the item is a user item, select its presentation and edit mode.

Fig. 251. ser Setting Property
The Custom settings item propertiy command can be used to set up user settings for the current structure item in the settings structure list. Each structure item has got its own list of adjustable items.
|
Object |
Adjustable Items |
|
|
Report |
■ |
Selected fields |
|
|
■ |
Order |
|
|
■ |
Filter |
|
|
■ |
Conditional appearance |
|
|
■ |
List of group |
|
Group/ table group/ chart group |
■ ■ ■ |
Group Selected fields Filter |
|
|
■ |
Order |
|
|
■ |
Conditional appearance |
|
|
■ |
List of nested groups |
|
Chart |
■ |
Chart |
|
|
■ |
Selected fields |
|
|
■ |
Conditional appearance |
|
|
■ |
List of series groups |
|
|
■ |
List of point groups |
|
Table |
■ |
Table |
|
|
■ |
Selected fields |
|
|
■ |
Conditional appearance |
|
|
■ |
List of row groups |
|
|
■ |
List of column groups |
|
Nested schema |
■ |
Nested report |
|
|
■ |
Selected fields |
|
|
■ |
Filter |
|
|
■ |
Order |
|
|
■ |
Conditional appearance |
|
|
■ |
List of groups |
Depending on the call source, the Properties command of a user settings item can be used to modify various settings:
Filter list – user settings for the current item/filter groups,
List of output and data parameters – user settings for the current parameter,
Conditional appearance list – user settings for the current conditional appearance item.
Additionally the Custom Settings command of the structure table can open a modal form that displays user settings with their default values.
10.3.7.3. Editing User Settings
The UserSettings object is edited in a table (see fig. 253).

Fig. 252. User Settings Editor
TIP
It makes sense to designate settings as user settings (out of the various settings provided by the data composition system) if they are meant for report management by the end user. It is assumed that the user will only operate these settings.
For example, a query (functioning as a data set for the report) might contain many fields that can be used for filtering. However, the report developer believes there is a number of filter items that are used most frequently. Therefore, it is logical they can be designated as user settings. In this case the user can edit both "special" filter items (the Goods Item row on fig. 253) and the entire filter (the Filter row on fig. 253).
It also makes sense to designate the following settings as user:
Period or date – virtually or all reports
Groups and conditional appearance – for spreadsheet reports Account value – for accounting reports, etc.
For each report, the developer makes a decision as to what settings need to be designated as user settings in this report (or report variant).
10.3.7.4. Quick User Settings
The developer can single out certain user settings edited by the user most frequently (e.g., filter by product in the Product Inventory report or filter by organization in an accounting report). In this case a user setting can be designated as a quick setting (by selecting Quick access for the ViewMode property). These settings can be directly edited in a report form.

Fig. 253. Quick User Settings
The table used to edit user settings also has got the ViewMode property that defines whether all user settings or quick settings only are displayed.
If a user does not like the current quick user settings, they can change their content, such as exclude settings that will not be changed very often.
The user needs to run the More – Change settings assortment… (All actions – Change settings assortment…) command in the report settings edit window.

Fig. 254. Editing quick user settings
The left side of the form shows all the user settings that can be selected as quick settings, and the right side shows the settings currently being edited in the report form.
Filter editing forms and conditional appearance forms contain commands to edit the user settings item properties. Thus, the user can drag filter or conditional appearance items that are frequently modified to quick user settings.
You can also manage quick user settings in the settings edit form using the Edit in report form column. By default this is not shown in the form. You need to enable it using the All actions – Change form... command in the edit settings window.
In this case you can't add new settings, but you can quickly change existing settings.

Fig. 255. Edit in Report Form column
10.3.7.5. Settings Composer
The settings composer has the UserSettings property. It contains values of the edited user settings. The property cannot be written using the 1C:Enterprise script. Moreover, the settings composer has the LoadUserSettings() method that loads user setting values passed as its parameters.
The GetSettings() method can be used to obtain a copy of the current settings (with regard to the user settings).
The LoadSettings() method loads the passed settings into the settings composer (the user settings are re-filled on the basis of the passed data).
10.3.7.6. Fillup of User Setting Values
When user setting values are filled, appropriately filled items are added to the user settings for various settings items.
The UserSettingID property and the properties that are actually edited in the user settings are filled in the appropriate user items for the following types:
DataCompositionFilterItem, DataCompositionFilterItemGroup, DataCompositionConditionalAppearanceItem, DataCompositionParame- terValue, DataCompositionGroup, DataCompositionTableGroup, DataCom- positionChartGroup, DataCompositionTable, DataCompositionChart, NestedDataCompositionSchema.
An object of the appropriate type is created for the following types: Da- taCompositionFilter, DataCompositionConditionalAppearance, DataCom- positionOrder, DataCompositionSelectedFields. The object's collection is appended by items with the ViewMode property not set to Inaccessible.
There are some exceptions:
Items are not added if marked as user items. For example, a user filter cannot be appended by a filter item marked as user;
Items are not added if they contain user items. For example, a group of conditions cannot be added if it contains items marked as user;
The ViewMode property is not analyzed for nested items. They are either added or not added together with their parents.
A DataCompositionSettingStructure object is created for the following types: DataCompositionStructureItemCollection, DataCompositi- onTableStructureItemCollection, DataCompositionChartStructu- reItemCollection. The object contains groups that already exist in the structure. It can only include groups with the specified group fields (detail records are not added to the object). Groups are placed in the object until a detail record, branch, table, nested schema, unused group or user-structured group is encountered.
10.3.7.7. Applying User Settings
User settings are applied to the main settings in the GetSettings() method of the settings composer. The following actions are performed:
Item contents are copied to the appropriate user setting items for the following types: DataCompositionFilterItem, DataCompositionConditionalAppearanceItem and DataCompositionParameterValue.
Items stored in the main settings and marked as Inaccessible are left unchanged for the following types: DataCompositionFilter, DataCom- positionConditionalAppearance, DataCompositionOrder and DataCom- positionSelectedFields. Items from the user settings are moved to the main settings. They are added to the end of the collection for Filter, Selec- tedFields and ConditionalAppearance or to the beginning of the collection for Order.
The Use property is set in the appropriate main settings item (based on the User Settings Item Use flag) for the following types: DataCompositionFilterItemGroup, DataCompositionGroup, DataCompositionTableGroup, DataCompositionChartGroup, DataCompositionTable, DataCompositionChart and DataCompositionNestedObjectSettings.
An item of the main settings structure is searched for appropriate groups that are then correctly ordered for the DataCompositionSettingStructure type. Missing groups are created. Groups that could not be found in the user settings or have been disabled by the user are not deleted; instead, they are marked. It saves them for possible future use. User groups with an empty set of fields (detail records) are ignored.
10.4. DATA COMPOSITION TEMPLATE
A data composition template is represented by the 1C:Enterprise script DataCompositionTemplate object and consists of multiple nested objects. The data composition template is an instruction for the data composition system on how to perform data composition. The composition template already includes descriptions of area templates, texts of executed queries, group positions, etc.
10.4.1. Data Composition Template Sections
Each data composition template contains a variety of objects that describe its sections. Let us review these sections.

Fig. 256. Data Composition Template Sections
Data Sources
The data composition template can contain several data source descriptions.
A data source means a source from where data are retrieved. 1C:Enterprise infobase is used as a data source.
Data sources are described in the template's DataSources property that contains a value collection consisting of DataCompositionTemplateDataSource items.
Several data sources that specify one infobase using a connection string can be created.
Data Sets
The data composition template data sets contain a description of the data to be obtained in data composition.
They are described in the data composition template's DataSets property.
Several data sets can exist.
Nested data sets are treated as standard data sets. They are always associated with their parents. If a filter condition is specified for a nested data set, its association with the parent data set is considered inner.
Data Composition Template Data Set Field
A data set can contain descriptions of fields available for this data set. Fields with no descriptions in data sets are not available. If a certain field is present in a data set query but does not exist in the data set fields description, this field is not available for use.
Data set fields are described in the data set's Fields property that contains a value collection consisting of DataCompositionTemplateDataSetField items.
Data Composition Template Parameter Values
The data composition template can contain parameters in any of its expressions.
Parameter values are described in the data composition template's Para- meterValues property that contains a value collection consisting of DataCompositionTemplateParameterValue items.
Data Composition Template Data Set Links
Data sets within the data composition template can be linked. The data composition template describes links between data sets.
Data set links are described in the data composition template's DataSetLinks property that contains a value collection consisting of DataCompositionTemplateDataSetLink items.
Area Templates in Data Composition Template
During composition execution, area templates are output to the composition result. These area templates are also stored in the data composition template.
Templates are described in the data composition template's Templates property that contains a value collection consisting of DataCompositionTemplateAreaTemplateDefinition items.
Data Composition Template Body
The previous sections of the data composition template specify where to receive information. Indication of how to compose data is in the data composition template body. The data composition template body consists of separate items.
The following item types can be used:
Group – describes a group output to the result;
Detail records – describes the data set's detail records output to the result;
Table – describes a table output to the result;
Chart – describes a chart output to the result;
Template – describes templates used for output.
Table Group
It describes a table group and is represented by the 1C:Enterprise script DataCompositionTemplateTableGroup object.
A table group contains the same properties as an ordinary group, with the following differences:
Table group body and table group hierarchical body can only contain items included in the table body, i.e. only table groups, table detail records and table group templates. The hierarchical body can also contain a table hierarchical group that indicates a location where hierarchical group records are output; Table group templates are used as header and footer templates; The following properties can be used:
○ OverallsTemplate – specifies the template used to output overalls by groups and having the DataCompositionTemplateTableGroupTemplate type.
○ OverallsPlacement – describes the overalls placement for a group and has the DataCompositionTotalPlacement type.
Table Detail Records
They describe table detail records and are represented by the 1C:Enterprise script DataCompositionTemplateTableRecords object.
Table Group Template
A table group template describes templates used for outputting table groups and is represented by the 1C:Enterprise script DataCompositionTemplateTab- leGroupTemplate object.
Chart Group
It describes chart groups and is represented by the 1C:Enterprise script DataCompositionTemplateChartGroupBody object.
A chart group contains the same properties as an ordinary group, with the following differences:
The chart group body and chart group hierarchical body can only contain chart group templates and chart groups. The hierarchical body can also contain
a chart hierarchical group that indicates a location where hierarchical group records are output;
There are no header and footer templates.
Chart Group Template
A chart group template describes templates used for outputting chart groups and is represented by the 1C:Enterprise script DataCompositionTempla- teChartGroupTemplate object.
Area Templates
An area template is a declarative description of the output data position as well as the visual presentation required for the output of data to differently formatted documents.
There are several fundamentally different area templates:
The area template itself
Plan area templates
The template structure is shown on fig. 257.

Fig. 257. Template Structure
Area templates are represented by the 1C:Enterprise script DataComp- ositionAreaTemplate object. The latter is a collection of DataComposi- tionAreaTemplateTableRow objects.
10.4.1.1. Area Template Structure
As mentioned above, an area template is a collection of DataComposi- tionAreaTemplateTableRow objects. A Row is a collection of cells positioned horizontally from left to right. Thus, several adjacent rows of a data composition area table make a rectangular table.
Table Cell Collection
This object is a collection of table row cells. It is described by the 1C:Enterprise script DataCompositionAreaTableCells object. The collection consists of table cells that represent DataCompositionAreaTemplateTableCell objects.
A table cell is a rectangular area used for outputting data in differently formatted documents. Cells can contain output fields, text and formatting.
Template Item Collection
A template item collection (DataCompositionAreaTemplateItems object) is a collection of fields (DataCompositionAreaTemplateField objects). These objects can appear in the collection in an arbitrary order. Data in these objects is used for outputting to differently formatted documents.
Field
This item is a field output in a table cell or list item. A field can contain an arbitrary value and its appearance. A field is described by the 1C:Enterprise script DataCompositionAreaTemplateField object.
Table Cell Appearance
Table cell appearance is a collection of objects that describe the formatting of a table cell. It is described by the 1C:Enterprise script DataCompositionAreaTemplateTableCellAppearance object.
Field Appearance
Field appearance is a collection with a single object – the Format appearance item. It is described by the 1C:Enterprise script DataCompositionAreaTemplateFieldAppearance object.
10.4.1.2. Chart Area Template Structure
There are three types of plan area templates:
A chart template (DataCompositionAreaTemplateChartTemplate object)
A chart resource template (DataCompositionAreaTemplateChartResourceTemplate object)
A chart group template (DataCompositionAreaTemplateChartGroupTemplate object)
One chart template, one chart resource template and several chart group templates are generated when chart templates are created. The number of group templates corresponds to number of points and series in a chart.
Principle of Operation
Area templates are used for outputting reports to differently formatted documents. An area template is a component of the data composition template definition (DataCompositionSchemaTemplateDescription object).
In order to output values of the output report fields in area template cells or list items, assign a value of the DataCompositionSchemaParameter type containing the parameter name to the Value property of the data composition area field (DataCompositionAreaTemplateField object). Add the parameter itself to the template definition parameter list and assign it a parameter name and a name of the output field or expression in the data composition system expression language as its expression.
Chart Template
A chart template is used for describing the chart type. It is described by the 1C:Enterprise script DataCompositionAreaTemplateChartTemplate object.
Chart Resource Template
A chart resource template is used for generating chart values and is described by the 1C:Enterprise script DataCompositionAreaTemplateChartResourceTemplate object.
Chart Group Template
A chart group template is used to generate chart points and series. It is described by the 1C:Enterprise script DataCompositionAreaTemplateChartGroupTemplate object.
10.4.2. Appearance Templates
An appearance template is a declarative description of predefined report areas. These descriptions are used by the template area generator for template area generation based on data composition settings items.
To create an appearance template interactively, use the template wizard to specify the Data composition appearance template type and then click Finish. The appearance template window will open (see fig. 258).
The wizard window contains appearance area list, appearance setting table and spreadsheet document Preview fields that display the result of the settings selection.
Filled template areas are shown in bold.
Use the drag-and-drop context menu to copy appearance parameters from one area to another or to replace them.
The Standard template button loads a predefined template from the standard template list that also includes common configuration templates.
The Clear template button removes all appearance from a template.
To set up appearance, do the following:
Select an appearance area.
In the settings table, select parameters for changing and specify new appearance values.
Check results of the changes in the Example field.

Fig. 258. Appearance Template Window
If you want to output several group levels in the report, create an appropriate number of subordinate areas for each listed area containing levels. To create an area level, specify the area and press the Add command bar button. A row named Level N is added to the area list, where N stands for the group level number. Set appearance for the group level as described above.
NOTE
If several levels are set and a group level is removed, the lowest level in the current area is always deleted, even if another one is selected in the list.
Appearance Template Structure
Every appearance template consists of a certain number of appearance template areas. An appearance template area has a name – a string listing the appearance template areas and specifying for which area the given template is to be used and an appearance item collection.
An appearance item has two properties:
Level – a positive number; if the level is 0, the appearance is considered to be applied by default to all templates of an area of a certain type;
Appearance – a collection containing the appearance property names and their values.
Appearance templates are represented by the 1C:Enterprise script DataCompositionAppearanceTemplate object.
Data Composition Appearance Template
This object is a collection of appearance template areas. The collection is implemented as parameter values. The parameter name is an area name. An area name is a predefined string from the area list. The parameter value is a DataCompositionAppearanceTemplateArea object.
Data Composition Appearance Template Area
This object is a description of a predefined area and a collection of items of the appearance template area (DataCompositionAppearanceTemplateAreaItem objects).
Data Composition Appearance Template Area Item
This object is a description of a template area for a certain hierarchy level. If 0 is specified as a level number, then the appearance template is considered to be used for all areas of this type.
10.4.3. Generator of Template Areas
Use the template area generator to dynamically form data composition area templates used to output the data composition results in documents of various formats. An area template is understood as a declarative description of output data location and appearance.
Operation of the template area generator consists of the following stages:
Generation of common report templates
Generation of group templates
Placement of groups
Placement of output group fields
Use of an appearance template
Use of conditional appearances
Merging of cells
Let us consider every stage of the operation of the template area generator.
Generation of Common Report Templates
At this stage the template area generator creates common templates based on the data composition settings. The type and number of templates depends on an item type of the data composition setting.
Group Template
A special template – group header – is generated for a group. This template contains the names of the output fields in the left part of the template and names of the output resource fields in the right part of the template, as in the example below.
The following group of templates is generated for a table:
Table header template. This template contains the names of the output table row fields, as in the example below.
|
Contractor |
Contractor.Code |
|
|
Nomenclature |
Nomenclature.Code |
Nomenclature.Description |
Template of totals by rows. This template contains the Total special word and names of the resource fields if they are output horizontally, as in the example below.
Total
Count Sum
Template of totals by columns. This template contains the Total special word and names of the resource fields if they are output vertically, as in the example below.
Total
Overalls template. This template contains the resource fields that are output in the table and are required to display the overalls in a table, as in the example below.
Presentation(Sum(Sales.SalesVolume))Presentation(Sum(Sales.SalesVolume))
Location of the template data within the table is shown below.
|
Table Header |
Column area |
Total template by rows |
|
Row area |
Resource area |
Totals area by rows |
|
Total template by columns |
Totals area by columns |
Template of overalls |
The location of the totals templates by columns and rows is managed by the OverallsHorizontalLocation and OverallsVerticalLocation properties, respectively. The following options of the overalls location are possible:
None – overalls are not output.
|
Table Header |
Column area |
|
Row area |
Resource area |
Begin – overalls are output in the first column or in the first row of a table, respectively.
|
Table Header |
Total template by rows |
Column area |
|
Total template by columns |
Template of overalls |
Totals area by columns |
|
Row area |
Totals template by rows |
Resource area |
End – overalls are output in the last column or the last row of a table, respectively.
|
Table Header |
Column area |
Total template by rows |
|
Row area |
Resource area |
Totals area by rows |
|
Total template by columns |
Totals area by columns |
Template of overalls |
BeginAndEnd – overalls are output in the first column/row and in the last column/row of a table.
|
Table Header |
Total template by rows |
Column area |
Total template by rows |
|
Total template by columns |
Template of overalls |
Totals area by columns |
Template of overalls |
|
Row area |
Totals area by rows |
Resource area |
Totals area by rows |
|
Total template by columns |
Overalls template |
Totals area by columns |
Template of overalls |
Auto – column totals are located in the last row, whilst row totals are located in the last column.
Chart Template
This template contain the chart's appearance properties.
Generation of Group Templates
The data composition setting contains three types of groups:
Group
Table group
Chart group
Every group type has its own set of area templates. However, the location of groups relative to each other, the location of the output fields within the group areas and the location of the resource fields is unified. The following stages can be singled out in group area template generation:
Group template type identification. The group template type is obtained from the DataCompositionGroupTemplateType property of the DataCompositionOutputParameterValues object. This property is meaningful only for simple groups, i.e. groups that are not included in a table or a chart. The following location options are possible for the selected fields:
○ Auto – automatic identification of location for the selected fields: if a group contains a nested table, chart, nested report or group with a Vertical group template type, then the selected fields are located vertically, otherwise horizontally.
○ Horizontal – location of the selected fields is horizontal, from left to right.
|
Contractor |
Contractor.Code |
|
|
Nomenclature |
Nomenclature.Code |
Nomenclature.Description |
|
Alex-2002 |
00009 |
|
|
1C:Accounting 8 |
00013 |
1C:Accounting 8 |
○ Vertical – location of the selected fields is vertical, one under another.
|
Contractor |
Alex-2002 |
|
Contractor.Code |
00009 |
|
Nomenclature |
1C:Accounting 8 |
|
Nomenclature.Code |
00013 |
|
Nomenclature.Description |
1C:Accounting 8 |
Location of groups relative to each other. The location of groups relative to each other is managed by the GroupFieldsPlacement property of the DataCompositionOutputParameterValues object. The following location options are possible:
○ Together – groups are located under each other. Below is an example for groups by contractor and nomenclature.
|
Contractor |
Contractor.Code |
|
|
Nomenclature |
Nomenclature.Code |
Nomenclature.Description |
|
Alex-2002 |
00009 |
|
|
1C:Accounting 8 |
00013 |
1C:Accounting 8 |
○ Separately – each group is located in a separate area. The groups are located following each other from left to right. The output group fields are output in the nested groups as well.
|
Contractor |
Contractor.Code |
Nomenclature |
Nomenclature.Code |
Nomenclature.Description |
|
Alex-2002 |
00009 |
|
|
|
|
Alex-2002 |
00009 |
1C:Aspect 7.7 |
00015 |
1C:Aspect 7.7 Compact trading system |
○ SeparatelyAndInTotalsOnly – each group is located in a separate area. The groups are located following each other from left to right. The output fields are output only in this group:
|
Contractor |
Contractor.Code |
Nomenclature |
Nomenclature.Code |
Nomenclature.Description |
|
Alex-2002 |
00009 |
|
|
|
|
|
|
1C:Aspect 7.7 |
00015 |
1C:Aspect 7.7 Compact trading system |
Location of output fields. There are two types of fields: output fields (owner fields and/or their attributes) and resource fields. The output of these fields have considerable differences:
○ Output of fields. As mentioned above, there are owner fields and attribute fields. Owner fields are output in an area template in accordance with their sequence order in the data composition setting. Location of attribute fields is managed by a special AttributePlacement parameter of the DataCompositionOut- putParameterValues object. The following location options are possible:
□ Together – attribute fields are located together in a separate column and are separated by a comma when they are output.
|
Contractor |
Contractor.Code |
|
Nomenclature |
Nomenclature.Code, Nomenclature.Description |
□ Separately – every attribute field is located in a separate column.
|
Contractor |
Contractor.Code |
|
|
Nomenclature |
Nomenclature.Code |
Nomenclature.Description |
□ TogetherWithOwner – attribute fields are located together with their owner field in a separate column and are separated by a comma when they are output.
Contractor, Contractor.Code
Nomenclature, Nomenclature.Code, Nomenclature.Description
□ SpecialPosition – attribute fields are located in a special column of a group in the right-most position.
|
Contractor |
Contractor.Code |
|
Nomenclature |
Nomenclature.Code, Nomenclature.Description |
○ Output of fields located in folders. Use the Folder Placement property to manage the location of these fields. The following location options are possible:
□ Auto – fields are output depending on the group type. If a group is simple, the fields are output horizontally; if a group is of table type, then they are output vertically.
|
Contractor |
|
|
|||
|
Nomenclature |
Nomenclature attributes |
|
|||
|
Nomenclature.Code |
Nomenclature.Description |
Nomenclature.MainSupplier |
|||
|
Contractor |
|
|
||||
|
Nomenclature |
Nomenclature attributes |
|
||||
|
Nomenclature.Code |
|
|||||
|
Nomenclature.Description |
|
|||||
|
Nomenclature.MainSup |
|
|||||
□ Horizontally – fields are output horizontally from left to right.
|
Contractor |
|
|
|
|
Nomenclature |
Nomenclature attributes |
|
|
|
Nomenclature.Code |
Nomenclature.Description |
Nomenclature.MainSup |
|
□ Vertically – fields are output vertically one under another.
|
Contractor |
|
|
Nomenclature |
Nomenclature attributes |
|
Nomenclature.Code |
|
|
Nomenclature.Description |
|
|
Nomenclature.MainSup |
□ InSeparateColumn – fields are output in a separate column in the right-most position:
|
Contractor |
Contractor.Code |
|
|
|
|
Nomenclature |
Nomenclature attributes |
|
||
|
Nomenclature.Code |
Nomenclature.Description |
Nomenclature.MainSup |
||
□ Together – fields are output together and are separated by commas.
|
Contractor |
|
|
Nomenclature |
Nomenclature attributes |
|
|
Nomenclature.Code, Nomenclature.Description Nomenclature.MainSupplier |
○ Output of resource fields. Location of resource fields is managed through the special ResourcePlacement property of the OutputParameters object. The following location options are possible:
□ Horizontally – resource fields are located horizontally from left to right; □ Vertically – resource fields are located vertically one under another.
If a folder has no header, no space is left for the header in the template. In this case fields are output based on the Folder Placement property.
Use of Appearance Template
After the groups and fields are placed, the appearance template is applied to the created area. When the appearance template is applied, the previously defined appearance properties (such as BackColor or TextColor) are added to all the items of an area template. It is worth mentioning that there are many area appearance templates.
Use of Conditional Appearance
After applying the appearance template, conditional appearances are applied to the area template. Use the conditional appearance to add the appearance properties containing logical expressions to the area template. As a result of the calculation of a logical expression, a decision is made about what value of the appearance property must be used.
Merge Cells
A generated area template can have unfilled cells. Such cells must be merged to obtain a more visual representation of an area template. The following cell location options are possible:
Unfilled cells are located to the right of the filled cells. Cells that are located to the right are merged with the cells on the left.

Fig. 259. Unfilled Cells to the Right
Unfilled cells are located under the filled cells. Cells that are located below are merged with the cells above.

Fig. 260. Unfilled Cells at the Bottom
Unfilled cells are located to the right and under the filled cells. Cells that are located to the right are merged with the cells on the left. Then cells that are located below are merged with the cells above.

Fig. 261. Unfilled Cells at the Bottom and to the Right
10.4.3.1. Generation of Data Composition Template
The data composition template is generated on the basis of the data composition schema and settings. The data composition schema is created by the report developer and the settings are entered by the user.
The composition template is generated using the 1C:Enterprise script object, DataCompositionTemplateComposer.
This object has no properties and has one method (Execute()) which receives the data composition schema, data composition settings, variable where the DetailData object is placed and the appearance template. This method returns the created data composition template.
The template composer:
creates a composition template;
modifies the data set queries for obtaining the information the user requires and places them in the composition template;
generates filters in the query text or the data set description;
if necessary, creates data sets for obtaining and checking the hierarchy;
creates the required parameters with values set by the user in the data composition template;
fills in body items of the data composition template, in which it places groups, tables, etc. and fills in their parameters;
uses the template area generator (see page 1-624). If an appearance template is specified (parameter ¹ 4), this template is applied to the generated template;
creates the DetailsData object and places it in the passed variable if parameter ¹ 3 is specified. The created object should be used in the composition processor and in processing the details.
When the data composition template compiler generates a data composition template it analyzes the Group parameter value of the EvalExpression() function. If the parameter contains a name of the group that exists in the settings, the template compiler does not change this name. Otherwise, the template compiler searches in the current group's parent groups for the group with group fields containing all the fields specified in the Group parameter of the EvalExpression() function and then puts the name of the group found in this parameter.
For example, if the Nomenclature, NomenclatureCharacteristic string is specified as the parameter for the EvalExpression() function, then during the template generation the template compiler locates a group for the Nomenclature and NomenclatureCharacteristic fields and places the name of the group found into the generated template. The group is searched in groups that are available in the place where the group is evaluated. Thus, when the template compiler generates an expression for a table cell, the group will be searched in column groups for which a cell is displayed; row groups for which a cell is displayed; and groups in which a table is nested. Groups to which the EvalExpression() function can be applied are found in this way. If multiple groups are found, the closest group is selected. In a table, a group is searched in a row, then in a column, and then a group is searched above the table. If the group is not found, the expression is replaced with NULL.
Actually, this allows you to use EvalExpression() in user fields by specifying groups by group field names rather than by names alone.
Example:
DataCompositionschema = GetDataCompositionschema(); ExcutableSettings = GetExcutableSettings(); TemplateComposer = New DataCompositionTemplateComposer; CompositionTemplate = TemplateComposer.Execute(DataCompositionSchema, ExecutableSettings);
The created data composition template can be used for execution, i.e. for obtaining the result.
10.5. DATA COMPOSITION PROCESSOR
Data composition is executed using the 1C:Enterprise object, DataCompositi- onProcessor.
The data composition template is transferred to the processor input.
The operation of the data composition processor is very simple: after the data composition template has been set for the data composition processor, you can sequentially obtain the data composition result items from this object; you can then further use them, e.g. output into a spreadsheet document or save for further use.
Below is an example of working with the data composition processor:
FormElements.SDResultSpreadsheetDocument.Clear(); DCTemplate = GetCompositionTemplate(); DCProcessor = New DataCompositionProcessor; DCProcessor.Initialize(DCTemplate); OutputProcessor = New DataCompositionResultSpreadsheetDocumentOutputProcessor; OutputProcessor.SetDocument(FormElements.SDResultSpreadsheetDocument; OutputProcessor.BeginOutput(); While True Do DCResultItem = DataCompositionProcessor.Next(); If DCResultItem = Undefined Then Abort; EndIf; OutputProcessor.OutputItem(DCResultItem); EndDo; OutputProcessor.EndOutput();
When the data composition process is initialized, the following can be specified:
External data set object: a structure that contains the external data set name as its key and a data set as its value;
Details data: an object where drill down information is placed;
External function use feature: a flag that indicates whether functions of the configuration's common modules can be used.
10.6. FUNCTIONAL OPTIONS AND RIGHTS TO VIEW FIELDS IN REPORTS
When the system obtains the default report settings, it automatically does the following:
If the user has no rights to view a field interactively or the field is associated with the disabled functional options, it becomes unavailable for user setup. In other words, it is not displayed in the list of available fields.
If the field is linked to the attribute which type is disabled by the functional option then this field is removed from the list of available fields.
The query table and attributes of this table become unavailable if the functional options disables the configuration object that.
If the field that cannot be viewed by the user due to insufficient rights or is associated with a disabled functional option, is used in a user field, the user field is removed and is not used to set a filter.
The data composition system field is considered unavailable if all fields used in this field's expression are linked to disabled functional options. All fields included in the field query expression are used, as are any expressions from unions.
All fields that cannot be viewed by the user due to insufficient rights or are associated with a disabled functional option, are removed from the group fields. If you remove a group field and the group has no group fields with the enabled use flag, the entire group is deleted, while its contents (e.g., if the group includes a table) replaces the group.
If a row or column group is removed and the table has no other groups, the table is deleted.
If a series or point group is removed and the chart has no other groups, the chart is deleted.
All fields that cannot be viewed by the user due to insufficient rights or are associated with disabled functional options, are removed from the appearance fields of a conditional appearance item. If the appearance field is removed from the conditional appearance item and the item has no other appearance fields with the enabled use flag, the item is also deleted.
If a conditional appearance item filter uses a field that cannot be viewed by the user due to insufficient rights or is associated with disabled functional options, the conditional appearance item is deleted.
If a field used to be available and the user has saved its setting and loads it in the future (when the field is unavailable), the fields are not automatically removed from the setting. This functionality allows the user to replace unavailable fields by other fields or to remove their use from the settings.
If the AutoFillCheck parameter is set to True when the Execute() method of the DataCompositionTemplateComposer object is executed, the system checks whether fields are available to the current user and whether a field exists in an enabled functional option. If the settings use an unavailable field, an exception is raised. If the parameter is False, no check is performed.
NOTE
If a report is execute from an auto-generated form, the system checks whether fields are available to the current user and whether a field exists in an enabled functional option.
10.7. DATA COMPOSITION RESULT
The data composition result is a set of items of the data composition result. The data composition result does not exist as a 1C:Enterprise script object; only a set of items of the data composition result exists, with these items forming the result.
If necessary, items of the data composition result can be placed in a universal collection of values, e.g. Array, to manipulate the result as a whole.
The result items can be obtained using the DataCompositionProcessor object or they can be created and filled in by means of 1C:Enterprise script.
Use the output processor to output items of the data composition result in a spreadsheet document.
Review an example of data items below.
Item 1
|
Property |
Value |
|
Item type |
Begin |
|
Templates |
TableHeader, ColumnHeader, RowHeader, Resources |
|
Placement of nested items |
Vertically |
Item 2
|
Property |
Value |
|
Item type |
Beginning |
|
Placement of nested items |
Horizontally |
Item 3
|
Property |
Value |
|
Item type |
BeginEnd |
|
Template name |
TableHeader |
Item 4
|
Property |
Value |
|
Item type |
BeginEnd |
|
Template name |
ColumnHeader |
Item 5
|
Property |
Value |
|
Item type |
End |
Item 6
|
Property |
Value |
|
Item type |
Begin |
|
Placement of nested items |
Horizontally |
Item 7
|
Property |
Value |
|
Item type |
BeginEnd |
|
Template name |
RowHeader |
Item 8
|
Property |
Value |
|
Item type |
BeginEnd |
|
Template name |
Resources |
Item 9
|
Property |
Value |
|
Item type |
End |
Item 10
|
Property |
Value |
|
Item type |
End |
The output result for such items must look like the following:
|
TableHeader |
ColumnHeader |
|
RowHeader |
Resources |
If item 2 contained TableHeader and RowHeader templates, a template from this item would be used when outputting item 3; however a template from item 1 would be used when outputting item 7, as item 2 is finished with item 5.
The result items can be saved in XML using the standard tools, as shown in the example below.
XMLWriter = New XMLWriter;
XMLWriter.SetString();
XMLWriter.WriteStartElement("result");
DataCompositionTemplate = GetCompositionTemplate();
DataCompositionProcessor = New DataCompositionProcessor;
DataCompositionProcessor.Initialize(DataCompositionTemplate);
While True Do
DataCompositionResultItem = DataCompositionProcessor.Next();
If DataCompositionResultItem = Undefined Then
Abort;
EndIf;
XDTOSerializer.WriteXML(XMLWriter, DataCompositionResultItem,
"item", "http://v8.1c.ru/8/data-composition-system/scheme");
EndDo;
XMLWriter.WriteEndElement();
FormElements.DataCompositionResult. SetText(XMLWriter.Close());10.7.1. Composition Result Output to Spreadsheet Document
Use the DataCompositionResultSpreadsheetDocumentOutputProcessor object to output a report to a spreadsheet document.
Composition result items can be obtained using the data composition processor or generated by any other tools.
Below is an example of data composition result output in a spreadsheet document:
FormElements.SDResultSpreadsheetDocument.Clear(); DataCompositionTemplate = GetCompositionTemplate(); DataCompositionProcessor = New DataCompositionProcessor; DataCompositionProcessor.Initialize(DataCompositionTemplate); OutputProcessor = New DataCompositionResultValueCollectionOutputProcessor; OutputProcessor.SetDocument(FormElements.SDResultSpreadsheetDocument; OutputProcessor.BeginOutput(); While True Do DataCompositionResultItem = DataCompositionProcessor.Next(); If DataCompositionResultItem = Undefined Then Abort; EndIf; OutputProcessor.OutputItem(DataCompositionResultItem); EndDo; OutputProcessor.EndOutput();
You can also use the Output() method of the OutputProcessor object. Specify DataCompositionProcessor as a method parameter. In this case layout result output appears as follows:
OutputProcessor.Output(DataLayoutProcessor);
The data composition processor freezes the table tile if one table or one group is shown in the report (possibly with nested groups). You can manage the fixation (left and top) using the output setting FixedLeft and FixedTop.
10.7.2. Composition Result Output to Value Table and Value Tree
You can output the report to a value table or a value tree by means of the DataCompositionResultValueCollectionOutputProcessor object. The SetObject() method is similar to the SetDocument() method. If the SetObject() method is not called, the result is output to a value table.
Composition result items can be obtained using the data composition processor or generated by any other tools.
Below is an example of layout result output to a value tree:
TemplateComposer = New DataCompositionTemplateComposer;
DataCompositionTemplate = TemplateComposer.Execute(
DataCompositionSchema,
SettingsComposer.Settings,
,
,
Type("DataCompositionValueCollectionTemplateGenerator"));
DataCompositionProcessor = New DataCompositionProcessor;
DataCompositionProcessor.Initialize(DataCompositionTemplate);
OutputProcessor = New
DataCompositionResultValueCollectionOutputProcessor;
OutputProcessor.SetObject(ResultTree);
OutputProcessor.BeginOutput();
While True Do
DataCompositionResultItem = DataCompositionProcessor.Next();
If DataCompositionResultItem = Undefined Then
Abort;
EndIf;
OutputProcessor.OutputItem(DataCompositionResultItem);
EndDo;
OutputProcessor.EndOutput();The following limitations exist for layout result output to a value table or tree:
Settings must only contain groups and detail records. No tables, charts or nested reports are allowed;
All folders specified in the selected fields are ignored;
Neither conditional appearance nor field appearance specified in the data composition schema can be used;
Only the following output parameters are allowed:
○ Vertical placement of overalls;
○ Field header type; ○ Record count;
○ Records percent.
Predefined templates are not used.
Two template types are implemented to output results to a value table or tree: the Header Template (DataCompositionAreaTemplateValueCollectionHeader) and the Contents Template (DataCompositionAreaTemplateValueCollection).
10.8. CALCULATION OF TOTALS BY BALANCE FIELDS IN DATA COMPOSITION SYSTEM
In terms of the data composition template, a balance field is a field that has a Balance flag.
10.8.1. Calculation of Totals by Balance Fields
If the data composition template has a data set with an opening balance field, the data set must also contain a corresponding closing balance field and vice versa.
All the period fields described in the data set must have continuous numbering, starting with 1.
To calculate totals by data source fields correctly, the data must meet the following criteria: the period fields and dimension fields must be unique within the data, i.e.
data must not contain rows with identical period and dimension field values.
Use the following algorithm when calculating the totals by balance fields. If it is necessary to calculate the totals of a balance field for a group by a period field:
If the grouping has already been carried out by all the period fields:
○ For every combination of the dimension fields, by which grouping has been carried out:
□ record which is the closest to the current period is obtained;
□ if the obtained record corresponds to the current period, the opening and closing balance is obtained from this record;
□ otherwise if the obtained record has a previous period, a closing balance of the record is used as an opening and closing balance;
□ otherwise an opening balance of the obtained record is used as an opening and closing balance.
Alternatively (grouping has not yet been carried out by all the period fields):
For every combination of the dimension fields, by which grouping has been carried out:
○ the first and the last records in which fields of the used periods are equal to the current period are obtained;
○ if the records are found, then the first record is used as the opening balance and the last as the closing balance;
○ if records are not found, the closest record is obtained and its balances are used as the opening and closing balance, depending on whether the obtained record precedes or follows the current period.
Alternatively (grouping by the period field hasn’t been carried out):
the first chronological records for the unused dimension fields are used as records of the opening balance; the last records are used as records of the closing balance.
10.8.2. Calculation of Totals by Accounting Balance Fields
The calculation of the totals by accounting balance fields is similar to the calculation of totals by standard balance fields. In addition, the account field information is used when calculating totals by these fields. If totals are calculated for a group by an account field or if grouping by an account field precedes the group, for which the totals are calculated, the account type is used for calculation. Otherwise the account type is considered to be active/passive.
Depending on the type of account, the total balance is calculated using the following formulae:
If the obtained balance is > 0
|
|
Dr |
Cr |
|
Active |
Balance |
0 |
|
Passive |
0 |
Balance |
|
Active/Passive |
Balance |
0 |
If the obtained balance is < 0
|
|
Dr |
Cr |
|
Active |
Balance |
0 |
|
Passive |
0 |
Balance |
|
Active/Passive |
0 |
Balance |
10.8.3. Template Composition
To ensure the correct calculation of totals, the template composer executes additional actions when generating a template:
If the opening balance is used, it automatically adds the closing balance field to the query, even if it is not used and vice versa.
If the dimension attribute field is used, it automatically adds the dimension field to the query, even if it is not used.
10.9. WORKING WITH HIERARCHY IN DATA COMPOSITION SYSTEM
In the data composition system, the following items can be used within hierarchy:
Hierarchical groups
IN HIERARCHY condition
Let us consider the above items in more detail.
10.9.1. Hierarchical Groups
When a group is created, a user can specify that a hierarchical group is required for a certain field of the group.
For the system to carry out hierarchical grouping, the data composition processor must know where to obtain the data to build the hierarchy. This is implemented by creating a data set and linking it to itself.
Consider the following example. Assume it is necessary to build a hierarchy for the field of the Catalog.Nomenclature type.
The data set for the hierarchy looks like the following:
SELECT Nomenclature.Ref AS Ref, Nomenclature.Parent AS Parent FROM Catalog.Nomenclature AS Nomenclature WHERE Nomenclature.Ref IN(&Refs)
For this data set it is necessary to define the link from the Parent field to the Nomenclature field with the Ref parameter. Therefore, the data set can be used to obtain all the item parents in sequence.
The data set for hierarchy construction can either be expressly described in the data composition schema or automatically generated by the composer of the data composition template.
If the hierarchy data set is specified in the composition schema, it is necessary to add a query of the following type:
SELECT
Nomenclature.Ref AS Ref,
Nomenclature.Parent AS Parent
{SELECT
Ref.*,
Parent}
FROM
Catalog.Nomenclature AS Nomenclature
WHERE
Nomenclature.Ref IN(&Refs)This data set must be linked to itself, as described above. Additionally it is necessary to create a link to the data set from the field, for which the hierarchy must be built.
10.9.2. Hierarchical Detail Records
Detail records with hierarchy can be output to a report, using data set link settings.
For example, define the Nomenclature data set:
SELECT Nomenclature.Ref, Nomenclature.Parent, Nomenclature.Code, Nomenclature.Description, Nomenclature.IsFolder FROM Catalog.Nomenclature AS Nomenclature WHERE Nomenclature.Parent IN (&Parents)
Define the Nomenclature data set link to itself.
Set the Ref field as the source expression and the Parent field as the destination expression. Specify the Parents field as a link parameter that can get a list of parameters. Thus, the system selects the Ref field value from each row of the data set and retrieves records that contain this value in the Parent field. To ensure that child items are selected only in groups, set the link condition expression to be equal to the IsFolder field. Use the Value(Catalog.Nomenclature.EmptyRef) expression as the initial value of the hierarchical link. It means that at the top level of the hierarchical data set, records, where the Parent field is an empty reference to the Nomenclature catalog, are retrieved.
To output such a data set to a report, simply output detail records in the composition schema settings (add Code and Description to the selected fields list).
The result is shown on fig. 262.

Fig. 262. Hierarchical Detail Records
10.9.3. Output of a Single Item in Multiple Parent Records
When creating a hierarchy, the data composition system enables you to output a single item to several parent records.
Review an example.
Create two catalogs within the configuration: Children and Employees.
In the Employees catalog, generate the following records: Mary Jones, John Jones.
In the Children catalog, generate the following record: Samuel Jones.
Assume the Children information register contains the following records:
|
Child |
Parent |
|
Samuel Jones |
John Jones |
|
Samuel Jones |
Mary Jones |
Create a query for the Children data set which will get the list of children:
SELECT Children.Ref FROM Catalog.Children as Children
Additionally create a query for the Hierarchy data set which will get hierarchical records:
SELECT EmployeeChildren.Child AS Ref, EmployeeChildren.ChildParent AS Parent FROM InformationRegister.EmployeeChildren AS EmployeeChildren WHERE EmployeeChildren.Child IN(&Ref) MERGE ALL SELECT Employees.Ref, NULL FROM Catalog.Employees AS Employees WHERE Employees.Ref IN(&Ref)
The first query union selects the children's parents. The second part of the query selects employees, since the hierarchical set also has to contain hierarchical records.
Define links between the data sets.
Specify the Children data set as the link source and the Hierarchy data set as the destination. The Ref field is the source expression and another Ref field is the destination expression. Specify the Ref field as the link parameter and indicate that a list of parameters is allowed.
Define the hierarchical link. Link the Hierarchy data set to itself, Parent being the source field and Ref being the destination field. Specify the Ref field as the link parameter and indicate that a list of parameters is allowed.
IMPORTANT!
The hierarchical data set field that the data set is linked to must have the same name as in the source data set. Otherwise the system fails to obtain field attributes for the hierarchical set, nor does it obtain presentation for hierarchical values.
In the report settings, create the hierarchical group by the Ref field and switch the field’s presentation to Parent. Execute the report:

Fig. 263. Resulting Table
This will result in the Samuel Jones record appearing in both groups.
10.9.4. IN HIERARCHY Condition
Users can specify the IN HIERARCHY condition for a field. In this case the user should obtain records that are in the hierarchy of the specified reference.
If such a condition is specified in the global filter, this condition is included in the query text as the IN HIERARCHY condition. If the condition is not used in the global filter, the data composition processor must have the data set that contains the references meeting the condition, to process it.
Such a data set can be either expressly described in the data composition schema or automatically generated by the template composer.
10.10. USE OF DATA COMPOSITION SYSTEM IN APPLICATION DEVELOPMENT
When application solutions are developed, the data composition system can be used by the 1C:Enterprise script based on the object model described above.
Moreover, the data composition system can be applied in visual report generation. For example, after the Report configuration object is created, a template with a data composition schema can be generated for the report. To do this, click the Open button next to the Main data composition schema text box.

Fig. 264. Data Composition Schema Creation
The Open data composition schema button opens the main data composition schema. If no schema is available, a new one is created and assigned as the main schema.
All of the above actions result in opening the template wizard that can be used to create a template containing the data composition schema.

Fig. 265. Template Wizard
Clicking Finish opens the data composition schema wizard that is used to create a data composition schema (see page 1-547) or load an existing schema from an XML-document.
After the data composition schema is created, the report is ready for use and can be launched in the 1C:Enterprise mode. When the report is launched, the system auto-generates a report form and a settings form.
In addition to the main report form, the following can be selected at the Forms tab:
A report settings form that opens upon execution of the Settings command in the 1C:Enterprise mode and is used to specify parameters for user settings (see page 1-610).
A report variant editing form (to open it, select More – Change variant (All actions – Change variant) in the menu of the automatic report form) that can be used by advanced users to edit the current report variant (see page 1-599).

Fig. 266. Report Form Settings
If the forms auto-generated by the system in the course of report use and based on the data composition system, are not convenient for the end users, the application developer can create custom forms. It can be done in the report form wizard.

Fig. 267. Report Form Wizard
10.10.1. Input Parameters
Input parameters can be specified in the data composition schema for data set fields, calculated fields and parameters. These parameters describe how values are to be entered for fields in a filter or parameters. For example, Quick choice can be enabled for the Nomenclature field in the Inventory Balances report. This feature can later be used, when a filter by nomenclature is set up. A special selection form can be selected for the Warehouse field in the same report.
For details on input parameters see the built-in help.
10.10.2. Use of Metadata Object Properties in Reports
If a data composition schema uses a query data set, information about input parameters and some appearance parameters is retrieved from metadata objects for the data set fields. Thus, if the data composition schema does not have an input or output parameter, its value is automatically retrieved from an appropriate metadata object.
The following input parameters are retrieved from metadata objects:
Mask
Choice parameter links Link by type
Items of a link by type
Selection form
Edit format
Quick choice
Additionally the following output parameters are retrieved from metadata objects:
Format
Mark negatives Multiline mode
10.10.3. Background Report Execution
Situations may arise in the system operation process where reports are generated for a long period of time. It is is a good idea for a user to have the ability to perform operations in the system while a report is being generated. This ability is provided by the background report generation method (using background jobs).
An automatically generated form report uses background report execution in client/ server mode, and in the file mode version, direct report generation is used. If background report execution is not required in the client/server mode, you can use the ComposeResult() report form extension method, specifying the direct report generation attribute as the parameter.
Example:
ComposeResult(ResultCompositionMode.Directly);
If during background report generation user settings are interactively changed or the report variant is changed or selected, report execution will be stopped and the spreadsheet document will be shown with lighter colors.
If during background report generation the report form is closed, report execution will be stopped automatically, even if the StandardProcessing parameter is set to False in the BeforeClose report form event handler. Report execution is stopped (as well as the background job) after the OnClose report form event handler is called.
The status window can be displayed during background report execution. The status window will be generated if this is allowed (StatusAutoShowMode) and if the report is generated for longer than 2 seconds (4 seconds in the slow connection mode). The data composition system uses the ShowStatus property of the spreadsheet document field to show report status. If the report was generated for the specified time, the status is not shown and the result is shown instead.
Report generation completion is validated by the client application within the set period of time. The interval between every next validation is 1.4 times longer than the previous one (but not longer than 20 seconds).
The StatusAutoShowMode report form extension property is used to manage the report status display mode. This property specifies how the spreadsheet document showing report results will display report status. By default (e.g., for an automatically generated form) this property is set to Auto. This means that the status window will show that the report is up-to-date and is still being generated.
10.11. SPECIFICS OF USING OF DATA COMPOSITION SYSTEM
The data composition system does not allow use of data paths with names that are identical to keywords: CASE; WHEN; THEN; ELSE; END; IS; NOT; LIKE; ESCAPE; DISTINCT.
If a standard period parameter has an empty begin or end date, its nested BeginDate and EndDate parameters are considered unspecified. In other words, if the Period parameter has an empty begin date, the Period.Be- ginDate parameters is considered unspecified. A similar approach is used for the Period.EndDate parameter and the period end date. Consequently, parameters with expressions that use the Period.BeginDate and Period.EndDate parameters are also considered unspecified.
A query is invalid if it contains the DISTINCT keyword and its ORDER BY clause indicates an expression that is not in the selection list.
Grouping by period field attribute fields is not allowed.
If the user has no rights to view a metadata object interactively, the composition system makes all the object table fields unavailable. Assume the following query is used as a data set:
SELECT Doc.Ref.Date, Doc.Ref.Number, Doc.Nomenclature, Balances.Balance FROM Document.Invoice.Content AS Doc LEFT JOIN AccumulationRegister.NomenclatureAccounting.Balance Balances BY Doc.Nomenclature = Balances.Nomenclature
If the user has no interactive rights for the Invoice or Invoice.Content table, the Date, Number and Nomenclature fields are unavailable. If no rights are granted for the AccumulationRegister.NomenclatureAccounting table, the Balance field is unavailable. If the user has no rights to any tables, none of the fields is available.
The hierarchical data set field that the data set is linked to must have the same name as in the source data set. Otherwise attributes fields cannot be retrieved from the hierarchical data set.
If a dataset query in the selection list results in an expression representing usage of the REPRESENTATION() function to the expression in another field, the field getting the representation will not be available in settings when fields are automatically populated.
An error will occur during data composition when grouping is executed for the calculated field and the group requires an extension of the period.
Autoindentation is used only for the top left template cell in data composition system group templates.
If you use a batch query in the data composition system, the fields that are not used in the consequent batch queries are deleted from the list of selections and grouping fields. If a query that forms a temporary table does not contain a single field, the query is removed from the batch query. Data sets from which no fields are used are also removed from the resulting composition template. To prevent field removal, you need either to use the field, or to set the Required checkbox in the field role of a data composition layout.
When data composition result is is put to a collection of values the fields of different groups, that contain a reference to the one and the same data composition field, are put to the one column of the collection.
When MERGE or MERGE ALL is used in the data composition data set query with automatic filling of available settings and when a filter is applied to the field attribute, the filter is applied only in those parts of union where this attribute exists. A filter is applied only to fields with expressions that are not equal to 0.